


背景
全链路压测指的是基于实际的生产业务场景、系统环境,模拟海量的用户请求和数据对整个业务链进行压力测试,并持续调优的过程。常用于复杂业务链路中,基于全链路压力测试发现服务端性能问题。
随着公司业务的不断扩张,用户流量在不断提升,研发体系的规模和复杂性也随之增加。线上服务的稳定性也越来越重要 ™,服务性能问题,以及容量问题也越发明显。为了及时暴露服务的各种稳定性问题,我们了引入了基于线上全链路压测的工具、研发体系。
本文主要介绍字节跳动的服务端全链路压测体系,以及字节跳动各种业务的全链路压测实践。
压测方案
网络架构
-
目的
理解业务的请求在网络中是如何流转的,整个过程经过了哪些节点。业务请求经过的所有节点,都是压测的对象。在压测过程中,都需要关注其性能表现。
-
请求流转
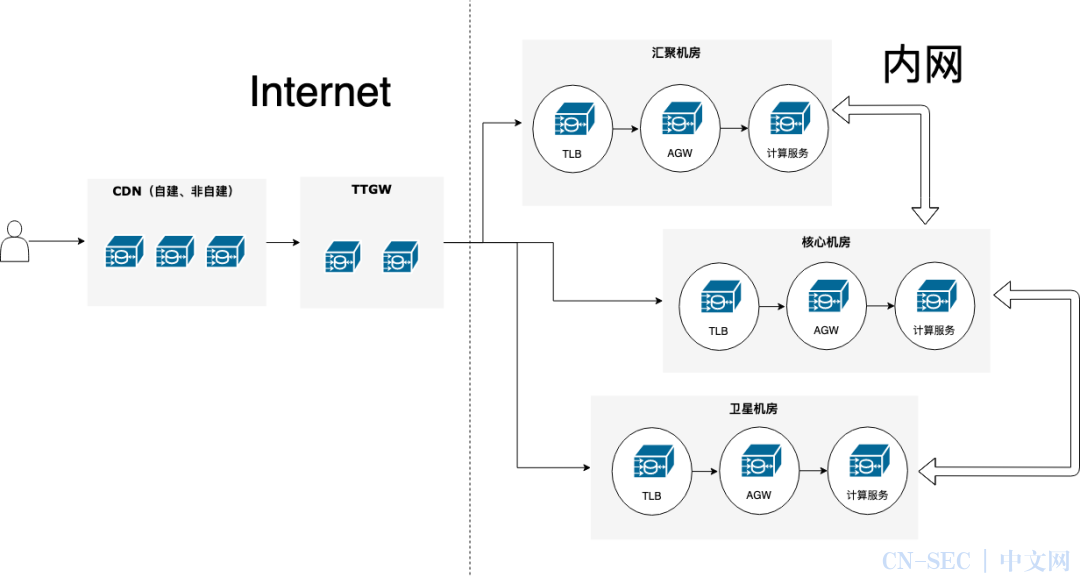
下图一个典型的网络架构,用户请求通过 CDN 溯源,经过 TTGW,TLB,AGW,然后才到达业务服务 PSM。(TTGW 是头条的高性能 4 层负载均衡网关,TLB 是七层负载均衡服务,AGW 是头条统一业务 Api 接入层)
压测目的与方案
在全链路压测体系第一步,压测人员必须明确压测目的,当明确压测目的后才能选择一个合理的压测方案。一个完整合理的方案可以提高全链路压测效率,减少没有意义的工作,节约了时间成本,对后续其他模块的压测或常态化压测提供了一定借鉴。
-
目的:在结合业务背景前提下,用户清晰把握明确性能测试的目的是什么?根据不同场景分类,有着不同目的,常见的场景如下:
| 场景分类 | 主要目的 | 典型场景 | 主要特点 |
|---|---|---|---|
| 能力验证 | 验证在给定的软硬件条件下,系统能否具有预期表现 | 当前服务已经部署了 n 台机器,能否支持 50 万用户同时在线访问 | 1、软硬件环境都已经确定 2、有明确的性能目标 3、需要根据业务场景来构造压测数据和请求 |
| 容量规划 | 关注如何使系统具有我们要求的性能 | 春节活动需要 X 亿人同时在线访问,系统需要如何调试?(性能优化,设计优化,资源预估) | 1、它是一种探索性测试 2、常用于了解系统现状 3、需要根据系统现状,对未来系统进行一个预估和规划 |
| 性能调优 | 主要用于对系统性能进行调优 | 系统响应越来越慢,此时该如何处理? | 1、对于代码级的优化,单实例压测即可 2、对于系统整体设计优化,需要集群压测,保证集群负载维持在一定水位 |
| 缺陷发现重现 | 发现/重现性能缺陷 | 服务线程死锁,内存泄漏等 | 1、需要对性能问题分类 2、针对每类问题构造对应的数据和压测策略 |
| 性能基准比较 | 系统新版本的性能验证 | 新版本的代码改动,是否有降低了系统性能,是否符合上线要求 | 1、有版本性能基准 2、固定环境因素的影响 3、AAB Diff 4、diff 置信度 |
压测目标
在网络架构图中,明确展示了各系统各司其职,它们分别负责将用户请求做相应处理并将请求流转至下游服务。因此,根据压测方案的目的,选择一个合理的压测目标,可以减少大量的压测工作,提高压测效率。
| 目的 | 压测目标 | 典型场景 |
|---|---|---|
| 压测带宽 | 从 CDN、TLB 处发压 | 春节活动需要 X 亿人同时在线访问,链路带宽是否足够? |
| 压测业务逻辑 | 从汇聚机房、核心机房、卫星机房的 AGW 和业务服务发压 | 用户零点秒杀,是否能够保障商品、订单等系统一切正常? |
| 压测异步消息 | 从 MQ producer 处发压 | 异步消息队列是否能够满足高压力场景? |
环境隔离
在字节内部,线下测试环境是不允许压测的,由于线下资源不足,与线上环境差异大,压测出来的结论并不能充分保证线上的性能情况。因此本文指的压测都是在线上环境的压测。下文将重点介绍字节的全链路压测环境。
压测标记
为了区分线上流量与压测流量,使服务可以针对压测流量做定制业务逻辑,服务架构体系在服务框架与服务治理层面设定了压测标记。
目的:
-
对于框架与服务治理体系而言,压测标记可以用于区分流量属性,并且做相应拒绝/通过操作。 -
对于业务服务内部而言,压测标记可以让业务方识别压测流量并做相应的业务逻辑处理。
原理:
-
通过特殊字段 stress_tag,对压测流量进行染色,且压测标记对应的 value 不为空的流量。 -
服务框架通过解析请求的 stress_tag,对接口上下文注入压测标识符,并透传至下游服务,完成全链路压测标记透传。
生效条件:
-
压测前必须做服务改造。在全链路中,所有服务必须将上下文透传至下游,保证压测标记能被框架识别且透传。
压测开关
为了强化压测流量的管理,服务治理体系引入了压测开关的概念。压测开关作为总控制,所有服务框架必须判断压测开关是否打开,若打开才能允许通过压测流量,若关闭则只能拒绝压测流量。
目的:
-
保护线上服务,避免线上服务在没有准备好的情况下,或不能压测的情况,受到压测流量的袭击 -
压测紧急处理,对于线上服务负载过大时,且无法停止压测流量时,可以通过压测开关拦截所有压测流量,避免出现线上故障
原理:
-
压测开关的表达方式是 etcd 的配置值,每个服务都会有一个特定的压测开关 key,value 为 on 表示打开状态,off 为关闭状态。存储服务的压测开关 key 各有不同。 -
每个服务每个集群都有一个压测开关(key = psm/cluster),控制该集群的压测流量 -
计算服务的压测开关状态都是由框架和 Mesh 来判断的,存储服务的压测开关状态则是由存储服务的 SDK 来判断的 -
压测开关没有打开时,压测流量会被服务框架或存储 SDK 拒绝
生效条件:
-
压测前必须打开整条调用链中所有服务的压测开关,否则压测流量会被框架/SDK 拒绝。(开关可以在 Rhino 压测平台打开)
存储隔离方案
对于压测数据的存储,必须将线上数据与压测数据做隔离,否则会导致压测数据量过大影响线上数据正常存取。
目的:
-
将压测过程中产生的测试脏数据与线上真实数据做隔离,防止污染线上真实存储。 -
存储隔离后,可以测试出预期存储条件下的性能。
原理:
-
各存储系统的 SDK 会对输入的上下文识别压测标识符,若存在压测标记,则走影子表存储,否则走线上存储。 -
部分 SDK 另外提供压测开关判断,用户需打开存储服务的压测开关方可存到影子表中。
生效条件:
-
压测前必须对代码做相应改造,并升级至最新版本的存储 SDK
平台搭建
Rhino 压测平台
它是一个多功能压测平台,支持多种场景、模式的发压。Rhino 统一管理了压测任务、压测数据、发压机、压测结果。集成了 Bytemesh、User、Trace、Bytemock、Bytecopy 等多个系统。

Rhino 压测平台支持以下能力
| Rhino 压测平台 | |
|---|---|
| 压测协议支持 | HTTP/HTTPS/protobuf/Thrift/其他所有(plugin)/TCP |
| 发压能力 | 日常发压实例数<400,2021 春节压测峰值 QPS=7000w 发压机可以无限水平扩容 |
| 多机房支撑 | CN/SG/US |
| 压测环境 | 支持线上线下环境压测,支持多泳道泳道压测 |
| 压测数据 | 用户构造 fake 数据 csv 文件数据流量 录制回放:录制数据保存在 hdfs,可以多次改写,回放。不受时间限制 |
| 研发流量整合 | 接入 Devops,发布前,对 stress 集群进行压测 |
| 性能 diff | 支持不同压测结果的 diff,支持 diff 压测基线 |
| 压测报告 | 客户端监控、服务端监控、下游监控、性能 profile,告警监控,性能分析 |
| 压测风险 | 压力太大,有将服务及下游打挂的风险 压测链路中存在写接口,如果没有改造,有数据污染的风险 |
| 风险控制 | 压测标记 & 压测开关 链路梳理 & 压测周知 告警监控自动停止压测流量 |
| 压测方式 | Fake 数据压测 流量录制回放 线上单实例流量调度 |
压测方式
根据不同业务的场景、以及压测的方案,业务方需要制定不同的发压方式,以达到压测预期效果。下面将介绍 Rhino 平台提供的四种发压方式,业务方需根据自身业务特点,选择适合的方式发压。
Fake 流量
Fake 流量压测是指用户自行构造压测请求进行压测。Rhino 平台支持 HTTP、Thrift 两种协议的 Fake 流量发压。
原理:

Fake 流量模式适合针对请求参数简单的接口压测,同时也适合针对特定请求进行压测。Rhino 平台会为每个请求注入压测标记。
典型场景:
-
新服务上线之前进行压测。 -
为了重现某种场景下造成的性能问题,构造特定参数的请求发压。 -
线上 http/thrift 服务已经在运行,且接口参数比较单一,快速压测接口 -
接入公司 passport lib 后,使用压测账号进行压测
自定义插件发压
为了支持更多的协议与更复杂的压测场景,Rhino 平台支持了 GoPlugin 发压模式。
原理:
依赖 golang 的 plugin 功能,运行时加载 plugin 文件,并加以执行
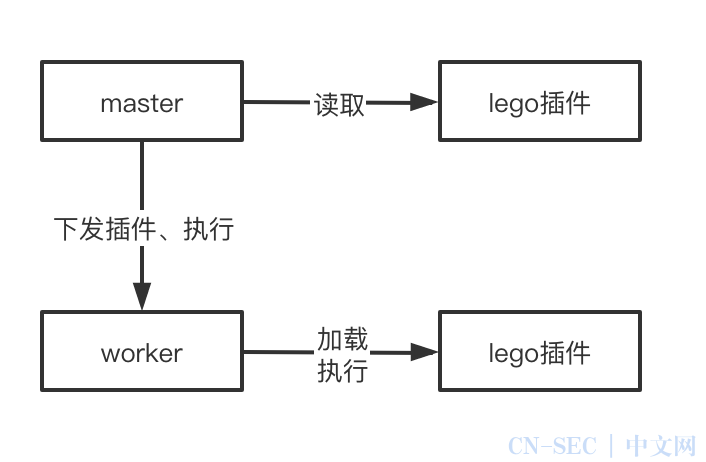
GoPlugin 发压模式适合灵活构造请求数据、支持自定义协议、支持自定义发压场景,相当于所有发压场景都可以通过代码实现。注意 Rhino 平台对于 GoPlugin 模式不会注入压测标记,用户需在插件内加上压测标记。
典型场景:
-
压测自定义协议的服务,如 websocket、gRPC 等 -
压测自定义的场景,如请求一个接口后等待 2s 再次请求第二个接口、请求第一个接口对返回值做相应的计算转换再请求第二个接口等 -
自定义的压测数据构造,比如从 DB、服务等获取压测请求数据 -
自定义的压测目标:比如要压测消息队列,可以通过构造一个 GoPlugin 对 producer 发压
流量录制回放
为了使压测更贴近线上请求,Rhino 平台支持了流量录制回放的发压模式,平台经过线上流量采集、线上流量改写为压测请求、压测流量回放三个步骤,将线上请求回放到压测目标中。
原理:
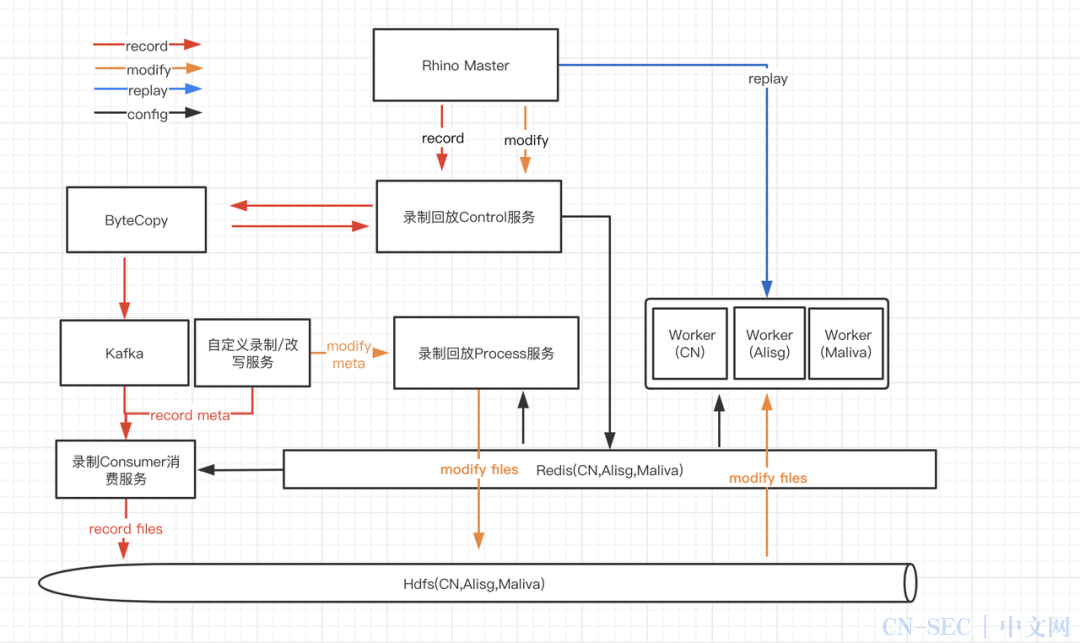
依赖 bytecopy 的采集流量能力,要求服务已经部署到线上,开启 mesh,且有流量可以采集。
典型场景:
-
构造压测请求比较复杂,且服务已经上线,线上有流量可供采集 -
压测需要模拟线上请求的分布,避免 hot key,如搜索 query -
希望将线上流量放大 N 倍,录制线上流量并回放到特定压测目标 -
希望录制线上流量,同时执行复杂的改写规则用于回放
流量调度
对于服务维度而言,如果想测试服务能承载多少 QPS,每个接口的 QPS 分布情况,流量调度是一个比较合适的压测方式。Rhino 平台支持了单实例的流量调度模式压测。
原理:
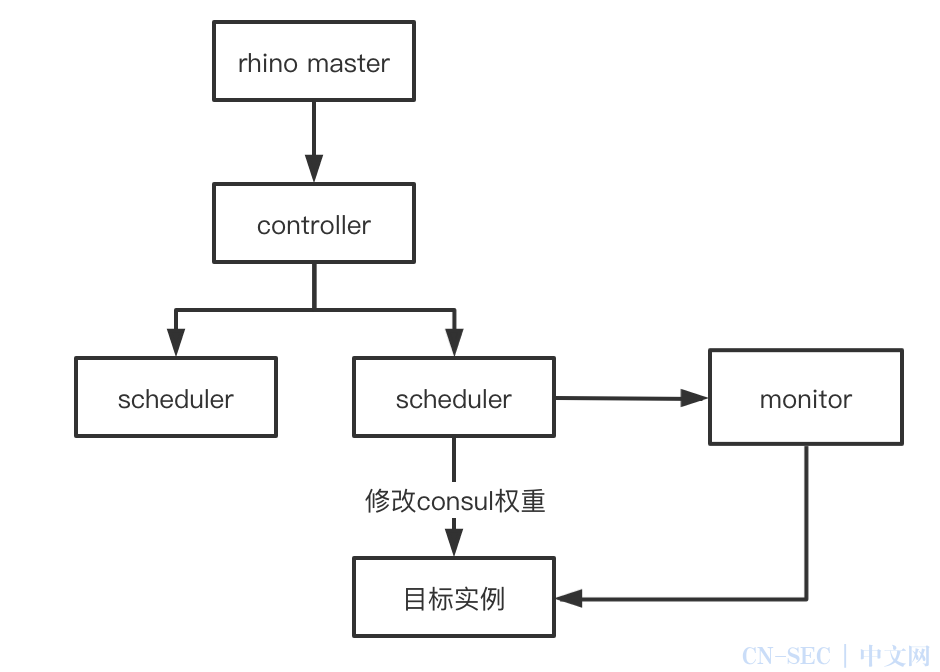
scheduler 修改被测实例的 consul 权重,使流量不断打到目标实例中,而其他实例流量相应的减少,保持服务的总流量不变。压测的请求完全来自线上流量,不使用压测标识,因此压测流量的流转、存储均保持线上模式。同时 scheduler 会监控目标实例的服务指标,当服务指标到达阈值后将停止压测,将 consul 权重恢复至初始值。
典型场景:
-
希望评估当前服务能够承载多少 qps,每个接口分别承载多少 qps,可将压测结果用于服务容量评估 -
不希望对代码做压测改造,快速增加单实例的压力
压测方式对比
下面将上述压测方式在压测目标、压测场景、优缺点维度下做对比,方便业务方选择合适的方式用于压测。
| 压测方法 | Fake 流量压测 (Http &Thrift) | 自定义压测(Plugin) | 自定义压测(Plugin) | 流量调度 |
|---|---|---|---|---|
| 作用目标 | 集群或单实例 | 集群或单实例 | 集群或单实例 | 单实例 |
| 压测场景 | 单接口/多接口(场景/流量配比) | 单接口/多接口(任何形式) | 单接口/多接口(场景/流量配比) | 服务维度 |
| 应用场景 | 线上/线上 http thrfit 接口 新上线的服务 压测方案为明确性能优化计划 |
线上/线上任意协议接口接口 单服务复杂压测场景 跨多个服务混合场景 |
压测数据构造复杂,要求数据多样性强 线上数据快速压测 |
单实例容量测试 |
| 缺点 | 压测数据构造形式单一 | 对用户代码能力要求较高 任务需要自行调试 |
需要线上服务有流量 服务开启 mesh 开关 |
线上流量充足 单实例不能线性反应整条链路的性能 |
监控
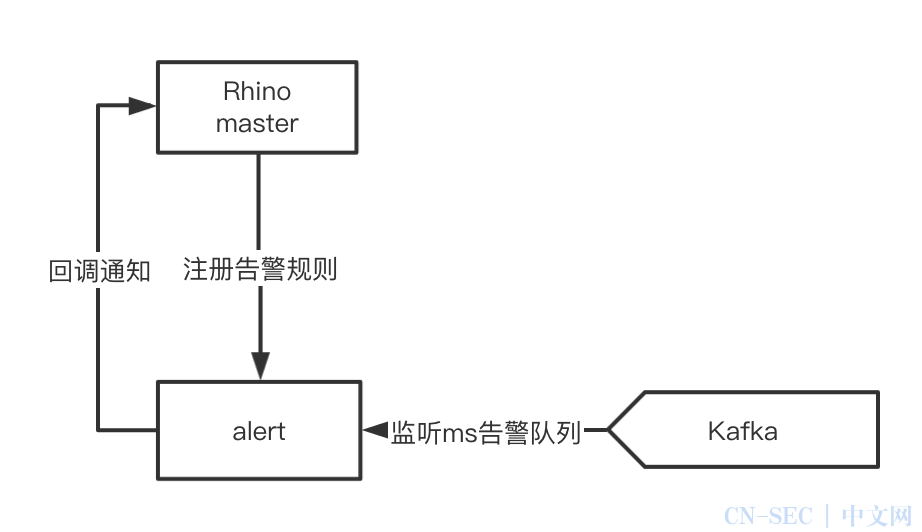
为了使压测结果更准确、使被测服务在压测过程中更安全,Rhino 平台开发了一套压测专用的报警监控体系。分为实时客户端监控、被测服务端监控、Ms 报警监控。
实时监控
公司的服务监控体系是基于 metrics 的 30s 一次聚合,但是对于压测任务而言,意味着观察压测状态需要等待 30s 的延时,这基本上是不能忍受的。因此 Rhino 平台支持了发压客户端维度的秒级监控,使用户可以及时观察压测状态,当压测出现异常时可以立即停止压测。
实现方案:

服务端监控
Rhino 支持服务端角度的全链路监控,包括服务监控、机器资源监控、上下游监控。目前使用的是 grafana 面板展示,将全链路每个服务 metrics、机器 influxdb 数据聚合展示到 grafana 中。未来将使用 Argos 展示服务端监控数据。
Ms 报警监控
此外,Rhino 平台还支持监控 ms 告警规则,当被测服务或下游服务触发了告警规则后,压测任务便自动停止,防止造成线上事故。
实现方案:
分析&优化
最后,压测完成后,如何分析压测问题,并作出相应优化通常是业务方最关注的问题。下文将列举几种分析方法,以及常见的性能问题及优化方式。
分析方法
监控分析
可以从发压客户端监控、被测服务端监控发现异常,异常主要包括:
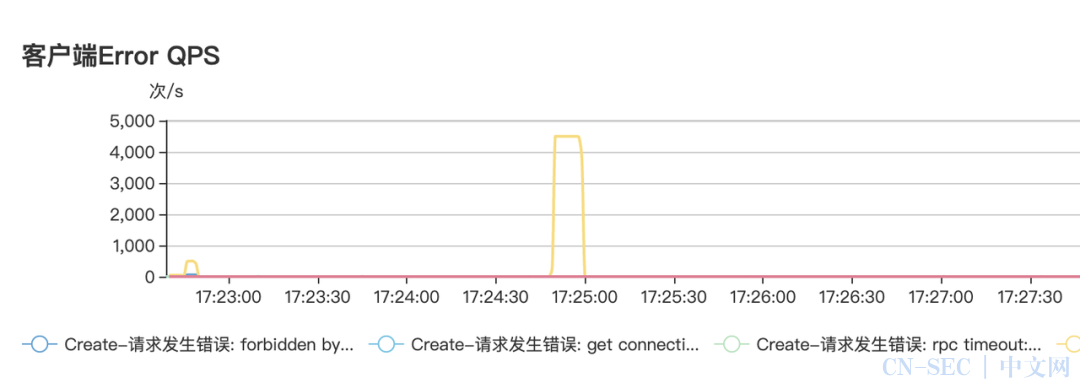
-
尖刺现象,查看错误日志,抓请求重现
-
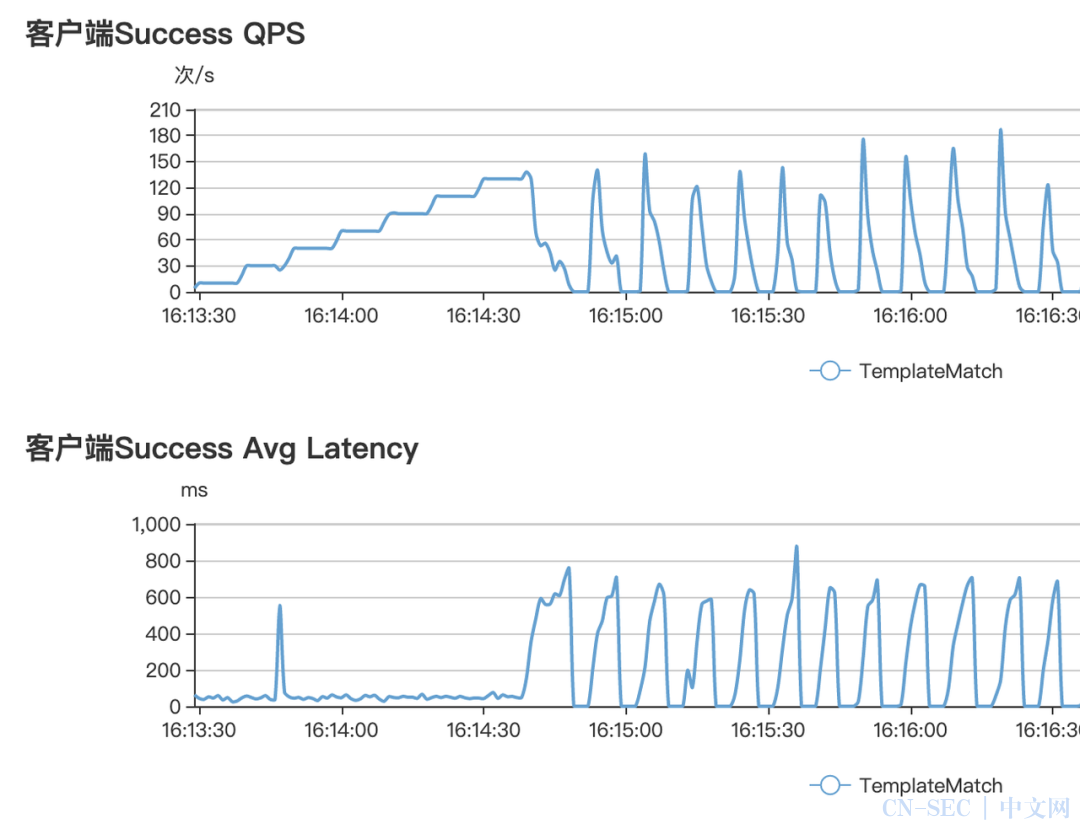
压力到达瓶颈,性能开始下降,接口延时上升,需要查看 pprof 对各项指标做相应分析
-
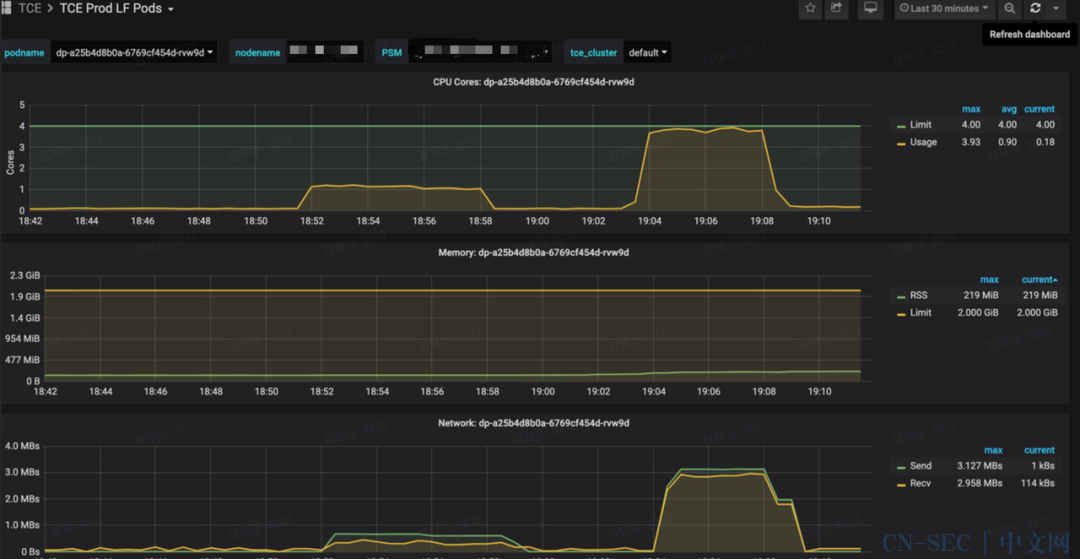
被测服务某一资源被打满,查看 cpu 耗时统计,找出耗时的模块
-
流量/延时分布不均,查看 agw 是否正常分配流量,查看存储 sharding 是否正常
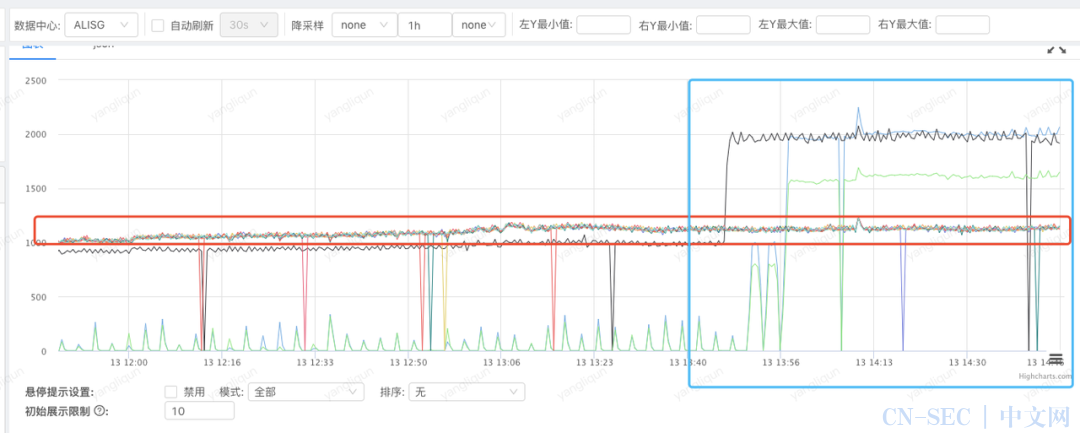
-
流量/延时分布不均,查看 agw 是否正常分配流量,查看存储 sharding 是否正常
-
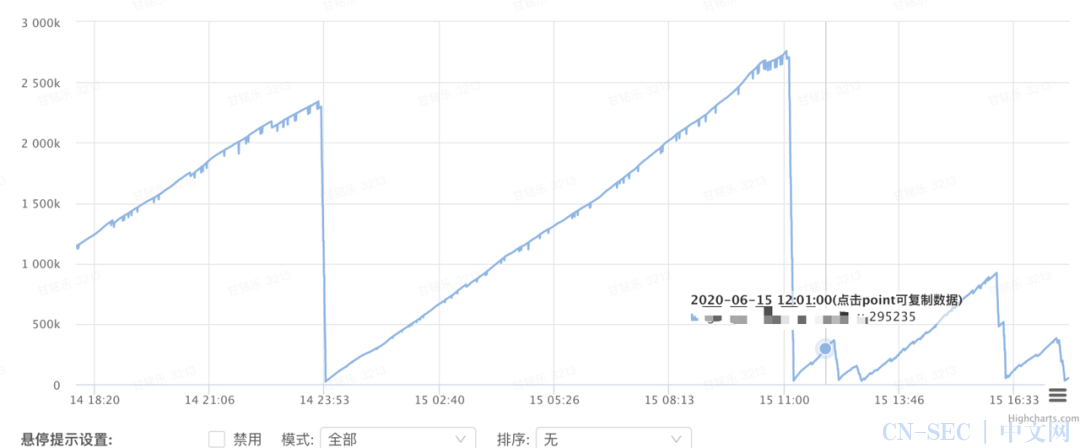
协程数量大涨,且没有下降趋势,协程泄漏,检查代码协程使用
Lidar 性能平台
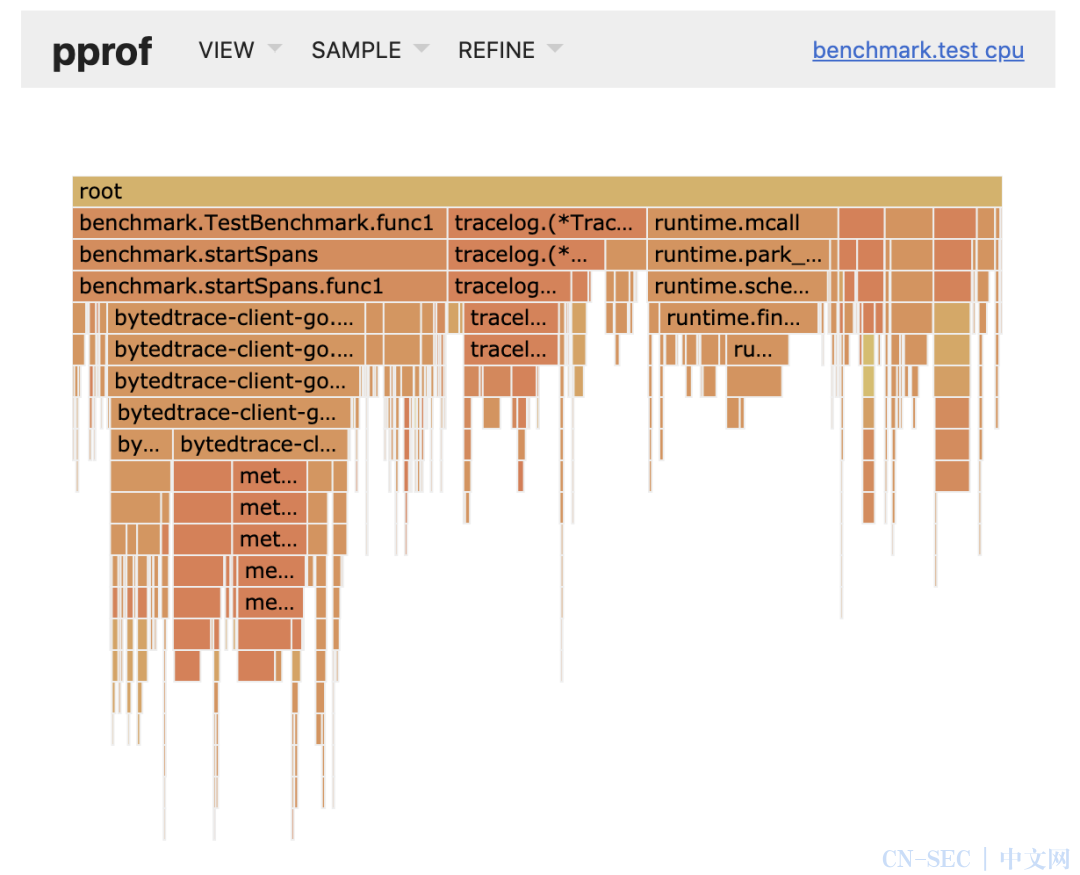
用户可以通过 Lidar 性能分析平台做服务的 pprof 分析,lidar 平台支持分析 golang、python 语言的服务,分析的指标包括 cpu 使用率、内存使用、协程数、线程数、阻塞时间。一般分析 Top 使用率,如果 TopList 展示了不正常的元素,应该关注这个异常元素。
系统层 tracing 分析
-
基于宿主机系统层面的 cpu、topN 函数分析
常见问题
-
服务的 CPU 陡然升高,RPC 调用和 consul、etcd 访问频繁超时,以及 goroutine 数目大涨。
-
可能是频繁创建 kitc client,每个调用创建一次。正确用法是只初始化一次 client,重复使用
-
调用 http 接口,协程泄漏
-
可能是 http connection 未释放,常见的代码问题是 http.Body 未 Close
-
内存 RSS 一直升高,没有下降趋势,内存泄漏
-
内存泄漏可以根据 pprof top list 查看最高使用的函数/对象,并作出优化调整
-
性能瓶颈为写数据库
-
可以尝试加入写 proxy 解决
-
redis 连接超时
-
需要增加 redis client 连接数
-
发压压力很高,但被测服务 cpu 却一直未跑满
-
有可能是用到了锁,需要 profile 排查一下
加入我们
字节跳动环境治理与容灾团队,负责整个字节跳动线下环境治理与效能工具建设,支持抖音、TikTok、头条、西瓜、番茄小说、电商、游戏、教育等众多产品线。我们致力于通过技术中台、与基础架构团队合作等方式,帮助业务提升服务端测试效率,团队下产品包括字节环境治理、全链路压测平台、数据构造平台、推荐 Mock 平台等。欢迎更多同学加入我们,构建行业顶尖的服务端工具。感兴趣可以联系邮箱 [email protected] 并注明 环境治理与容灾方向。
点个在看杀个 Bug ❤
相关推荐: 【安全头条】APT-C-36手段翻新躲检测,冒充南美组织作乱
第123期 你好呀~欢迎来到“安全头条”,站长小安将为大家奉上新鲜、实时、有趣的安全热点。在文章底部时常交流、疯狂讨论,都是小安欢迎哒~如果对本小站的内容还有更多建议,也欢迎底部提出建议哦! 1、硬气! 纽约小城拒付千万美元勒索赎金 月初,扬克斯市政府计算机遭…
- 左青龙
- 微信扫一扫
-

- 右白虎
- 微信扫一扫
-

评论