


开头随便唠两句,嫌啰嗦的可以直接看正文去喽,哈哈。首先祝大家新年快乐,2021有更大的收获。即将过去的2020有开心的事也有烦心的事,想了想最后一天还是要以一篇简单的爬虫结尾。最近两个月发生有太多事情,以致于没有精力去更新文章,现在才发现随着年龄增长遇到的事情也越来越多,有些时候的确有点分身乏术,现在社会年轻人的压力越来越大,疯狂加班的同时也要保重身体啊。事情虽多但是又不想因为这些事情松懈和禁锢自己,遂萌生做一个小程序的想法,不过手上没有数据,最终选定了几个网站进行采集,这些数据都是公开的,没有什么保密性。以前都是逆向,今天来一个简单爬虫。

XPATH解析
支持的朋友关注一下文末的公众号,当然不关注也无所谓。具体网站就不公开了,的确有兴趣的私聊我吧。都是小网站,基本上爬取都比较简单,这里记录的目的无非就是提供一些爬虫中遇到问题的解决思路给新手朋友们参考,顺便一提,根据以往的经验往往解析数据的时间占了爬虫的一半以上。
一开始爬取的过程中顺风顺水,设计的xpath解析语句也亲测有效:

当正式开始爬取的时候发现出来了很多不完整的。然后又去仔细查看了一番,发现当页面内容较多的时候,会出现一个阅读更多的按钮,这个按钮把剩下的部分隐藏了,我一开始测试的那个页面内容较少,也就没有阅读更多的按钮。
阅读更多
点击阅读更多按钮即发起一个ajax请求:
提交的数据从url也能看出来就一个id。
进行到这一步又是熟悉的味道,从调用栈进去吧。
调用栈一个是名字比较奇怪的,另外一个是jquery,那当然是进入名字比较奇怪的。进去以后就直接定位到了发起ajax请求的地方:
可以看到有一个idjm的变量,基本断定这就是请求中的id。上下翻了一下并没有看到赋值的地方,那这应该是一个全局变量。搜索一下找到了一个地方:
好了,看来真相在函数名为fanyiShow(id,idjm)里,那就看看在哪里调用了这个函数。全局搜索一下并没有找到调用的地方。
fanyiShow
js文件里都找不到调用这个函数的地方,想了一下,既然没有调用的地方,那是不是就直接在html文件里了,点击Elements在文件里搜索了一下,发现还真有。
给了onclick函数。传递了两个值,一个不知道是干啥的,另外一个就是ajax请求需要传递的值。那就用正则表达式把这几个值提取出来吧,
id = re.findall("fanyiShow/(([0-9].*?)/,",html) idjm= re.findall("fanyiShow/([0-9].*?/,/'([0-9A-Z]{14,17})",html)随后用python试了一下的确可以获取到返回。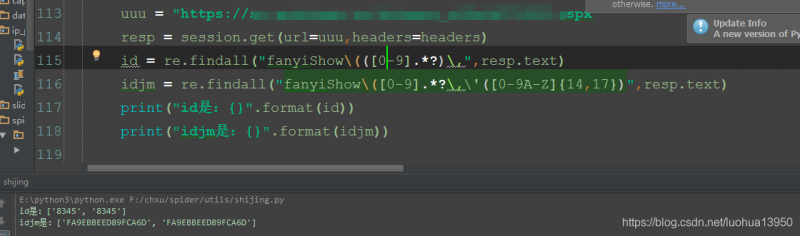
idjm拼接到后面再运行:
那这里就搞定了,继续爬取呗。
变化的ID
在运行过程中又卡壳了,原因在于这个xpath语句中有一个动态变化的值。
//div[@id='fanyi8349']/div[@class='contyishang']//text()fanyi8349是动态变化的,每个页面的值都不一样,比如:
页面一:
页面二:
一个是8345,一个是8349,其他页面也是不一样的。细心的同学应该发现了这个值不就是前面fanyiShow中的第一个参数么,那就好办了,前文正则表达式都已经拿到了,直接拼接一下xpath表达式即可。
其它问题
在爬取中请求多了还遇到ajax请求直接返回未登录的提示,但是我又是一个比较懒的人,根本不想去登录,所以去查看了一下cookies:
发现有一个字段login=false;,我就想我改成login=true;,这样我不就登录了,哈哈,试了一下果然可以,还是小网站好,没有那么多互相提防的东西,人与人最起码的信任还是有的。
结束
本文内容简单,只是提供一种灵活的思路,爬虫过程中不断的思考如何使用最有效率的方式来爬取和设计比较通用的解析方式才是爬虫比较高的境界。觉得有帮助关注一下知识图谱与大数据公众号吧,有大量抠JS代码的文章,当然不关注也无所谓。

- 左青龙
- 微信扫一扫
-

- 右白虎
- 微信扫一扫
-

评论