


前言
爷爷,你的骑砍2发售了!!!骑马与砍杀2:霸主 抢先体验版于2020年3月31日发售,到今天砍友们已经畅砍了一周,从中文站快速更新版本的消息来看,目前体验版还存在很多bug,希望经过这段时间的完善能让正式版更加具有可玩性。当然,今天不是来做游戏试玩,我们还是希望能通过爬取骑砍吧的一些评论看看发售前和发售后大众的态度,不废话了,开始。
准备工作
工具
- mongdb
- xpath库
- requests库
- xpath-helper
锁定网站
因为骑马与砍杀吧混有太多1代内容,这里选择了骑砍2吧作为目标。百度搜索骑砍2吧即可进入贴吧中,或者点击这里(https://tieba.baidu.com/f?kw=%C6%EF%BF%B32),进入后按照惯例F12打开开发者模式,切到Network页面,F5刷新页面,现在呈现应该如下图所示:
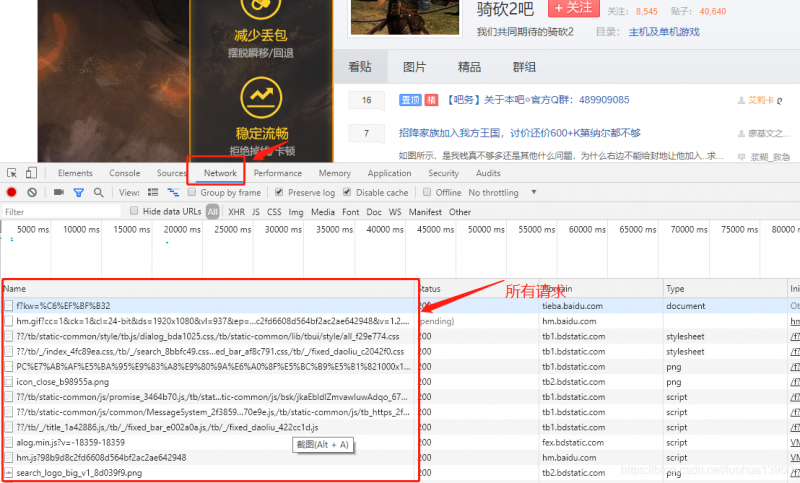
切到Doc选项,发现只剩一个请求,点击这个带有奇怪字符(红色箭头)的请求: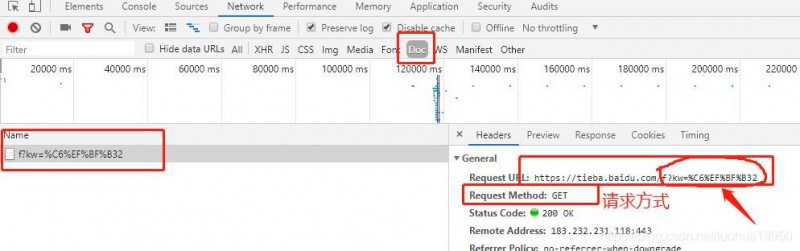
有兴趣可以把这个URL解码看看,百度很多,这里就不列出网址了: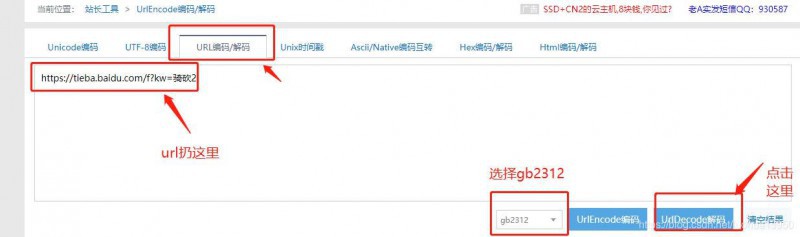
可以从上图看到那一串字符就变成了骑砍2,这里其实也不难猜测url里kw二字其实就是keywords的意思,骑砍2换成随意一个词都能跳转到对应贴吧。接下来切到Element页面,开始定位资源,会发现页面资源很多,这时候可以切换到移动端模式会简洁一点: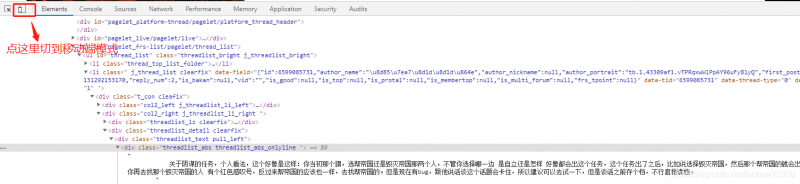
移动端模式感觉少了很多乱七八糟的东西:![爬虫学习(2):贴吧之骑马与砍杀2,愿它长寿?]()
提取贴子内容
点击左下方箭头选项用鼠标定位贴子内容元素,观察规律,不难发现贴子都在li标签下:

看看li标签下的样式:![爬虫学习(2):贴吧之骑马与砍杀2,愿它长寿?]()
想要的两个信息已在上图展示,ul里包li的关系已经知道,接下来就是如何提取,打开xpath-hepler,下列xpath语句将选中所有li:


//ul[@class='threads_list']//li[@class='tl_shadow tl_shadow_new ']
由于贴子内容是被div class="ti_title"包围的,即可使用下列语句,以第一个li为代表:
#这里1表示第一个li //ul[@class='threads_list']//li[@class='tl_shadow tl_shadow_new '][1]/a[@class='j_common ti_item ']/@href
同样也可以得到贴子内容,ul,li前缀不变:
提取评论列表
进入一个贴子打开开发者工具查看,发现评论列表依然在ul–>li下面,评论内容则在div content下面: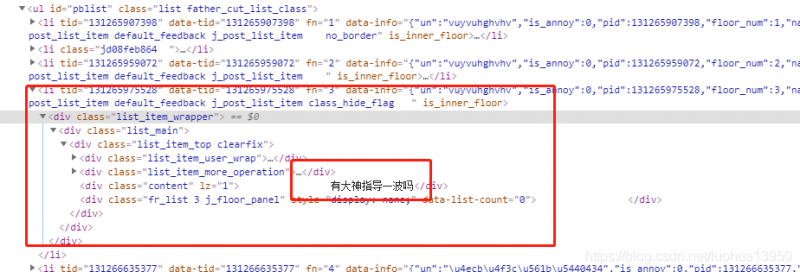
使用下图绿色框标注的嵌套规则即可写出xpath语句,进行内容提取:
翻页
页面内容已提取完毕,接下来就是要翻页,可以先看一下第一页的url,然后点击第二页对比不同之处:
点击第二页后,url中的pn从0改变到30:
https://tieba.baidu.com/f?kw=%C6%EF%BF%B32&pn=0& https://tieba.baidu.com/f?kw=%C6%EF%BF%B32&pn=30&
知道是如何翻页即可编写代码进行提取内容了。
代码
请求头
复制走即可
USER_AGENT = [ 'Mozilla/5.0 (Windows NT 6.1; rv:50.0) Gecko/20100101 Firefox/50.0', 'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0', 'Mozilla/5.0 (X11; Linux x86_64; rv:50.0) Gecko/20100101 Firefox/50.0', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.98 Safari/537.36', 'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0; Trident/5.0)', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/602.2.14 (KHTML, like Gecko) Version/10.0.1 Safari/602.2.14', 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.71 Safari/537.36', 'Mozilla/5.0 (iPad; CPU OS 10_1_1 like Mac OS X) AppleWebKit/602.2.14 (KHTML, like Gecko) Version/10.0 Mobile/14B100 Safari/602.1', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.11; rv:49.0) Gecko/20100101 Firefox/49.0', 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:50.0) Gecko/20100101 Firefox/50.0', 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:45.0) Gecko/20100101 Firefox/45.0', 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36', "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36", ]翻页
可以添加cookie进行访问:
def run(self): #可有可无 Cookie = { "BAIDUID":"F8707632F4FA0F6C249A52BB3673626F:FG=1", "BAIDU_WISE_UID":"wapp_1585653783353_960", "BDORZ":"B490B5EBF6F3CD402E515D22BCDA1598", "BIDUPSID":"E7EAFAE7E18C12733A8DBD9965A34A2B", "mo_originid":"2", "st_sign":"0e4c42ab", "SEENKW":"%E9%AA%91%E7%A0%8D2", "TIEBAUID":"c1fb1068593f73ab692c2bd8", "TIEBA_USERTYPE":"7a4a7b31aab7064b5ea62053", } self.session.cookies = requests.utils.cookiejar_from_dict(Cookie) count = 1 for i in range(0,900,30): #这里进行翻页 resp = self.download_page(self.urls.format(i)) #转换为element对象 html = etree.HTML(resp.text) #解析、提取内容 self.parser(html) #随机睡眠 rd =random.randint(5,15) print("第{}页爬取结束,休眠{}秒...".format(count,rd)) time.sleep(rd) #记录页数 count +=1下载页面
虽说百度这种大厂不会去随便封禁一个IP,但是请求头是必备的:
def download_page(self,url,method="get",data=None,proxies=None,**headers_kwargs): #随机请求头 ua = random.choice(USER_AGENT) headers = { "User_Agent":ua } if headers_kwargs: headers.update(headers_kwargs) if method.lower() == "get": resp = self.session.get(url,headers=headers) elif method.lower() == "post": resp = self.session.post(url, headers=headers,data=data) return resp解析页面
利用了刚才上面使用的xpath表达式提取内容
def parser(self,resp): li_xpath = resp.xpath("//ul[@id='thread_list']//li") print(len(li_xpath)) for li in li_xpath: _times = li.xpath("div[@class='t_con cleafix']//span[@class='pull-right is_show_create_time']/text()") _title = li.xpath("div[@class='t_con cleafix']//div[@class='threadlist_title pull_left j_th_tit ']/a[@class='j_th_tit ']/text()") title = _title[0].strip() if _title else "" _context = li.xpath("div[@class='t_con cleafix']//div[@class='threadlist_abs threadlist_abs_onlyline ']/text()") context = _context[0].strip() if _context else "" _href = li.xpath("div[@class='t_con cleafix']//div[@class='threadlist_title pull_left j_th_tit ']/a[@class='j_th_tit ']/@href") href = _href[0].strip() if _href else "" info = { "评论内容": context, "标题":title, "链接": href } print(info) ret = self.client["tieba"].insert(info) #判断是否有评论,有的话进入评论页 if href: url = parse.urljoin(tb.prefix_url, href) rd = random.randint(10,15) print("详情页睡眠{}秒".format(rd)) time.sleep(rd) resp = self.download_page(url) html = etree.HTML(resp.text) self.parser_inner(html)评论页内容提取
def parser_inner(self,html): print("进入详情页") div_list = html.xpath("//div[@class='p_postlist']/div[@class='l_post l_post_bright j_l_post clearfix ']") for div in div_list: _context = div.xpath("div[@class='d_post_content_main ']//div[@class='d_post_content j_d_post_content ']/text()") context = _context[0].strip() if _context else "" info = { "评论内容":context, "标题": "",#标题其实就是贴子标题 "链接":"" } print(info) ret = self.client["tieba"].insert(info)数据

这是存入mongodb中的数据,当然实际还提取了发帖者、时间、评论数等等,这里就不展示了,有兴趣的可以自己写xpath提取。
词云展示
为了更加形象的查看提取的数据里都有哪些关键词,这里使用词云进行展示(笔者也不会其他的,随大流了)。没什么技术含量,只给出部分代码了。
加载数据
def load_data(self,collection="tieba"): tieba = self.client[collection] tb = pd.DataFrame(list(tieba.find())) return tb[:]jieba处理
#去停用词 def remove_stopwords(self,words): return [word for word in words if word not in self.stopwords and len(word)>1] def join_words(self,df): if df: self.words = self.words + " "+" ".join(df) #分词 def cut_words(self,text): #列表形式返回 return jieba.lcut(text) #生成器返回,节省空间 #return jieba.cut(text) def data_clean(self): data = self.load_data() data["评论内容"] = data["评论内容"].apply(self.cut_words) data["评论内容"] = data["评论内容"].apply(self.remove_stopwords) data["评论内容"].apply(self.join_words)词云
def to_wordcloud(self): list_1d = self.data_clean() wc = WordCloud(font_path="C:/Windows/Fonts/simsun.ttc",width=800,height=700) words = " ".join(list_1d) img = wc.generate(words) plt.figure(figsize=(15, 10)) plt.imshow(img) plt.axis('off') wc.to_file("发售前.png")发售前

可以看出结果分词后词云展示的还是相对准确的,主要的几个词可以理解为骑砍2是一款游戏需要什么配置、发售时间,但是右上角大佬是个什么鬼?
发售后

家族应该是游戏中的一种机制,BUG也醒目,说明发售初期还是存在不少bug的,如果玩过一代的话,这个也相对能理解了,期待正式版。
结束
贴吧爬取相对是比较简单,不过刚好可以练习一下xpath语法,今天就到这了。
更多内容请关注从今天开始种树
关注知识图谱与大数据公众号,获取更多内容。
- 左青龙
- 微信扫一扫
-

- 右白虎
- 微信扫一扫
-

评论