data=[16,25,39,27,12,8,45,63] print('冒泡排序法:原始数据为:') for i in range(len(data)): print('%3d'%data[i],end='') print() for i in range(len(data)-1,0,-1): #扫描次数 for j in range(i): if data[j]>data[j+1]: data[j],data[j+1]=data[j+1],data[j] print('第%d次排序后的结果是:'%(8-i),end='') for j in range(len(data)): print('%3d'%data[j],end='') print() print('排序后的结果为:') for j in range(len(data)): print('%3d'%data[j],end='') print()
def showdata(data): for i in range(len(data)): print('%3d'%data[i],end='') print() def select(data): for i in range(len(data)-1): for j in range(i+1,8): if data[i]>data[j]: data[i],data[j]=data[j],data[i] print() data=[16,25,39,27,12,8,45,63] print('原始数据为:') showdata(data) select(data) print('排序后的数据为:') showdata(data)
def showdata(data): for i in range(len(data)): print('%3d'%data[i],end='') print() def insert(data): for i in range(1,len(data)): tmp=data[i]#tmp用来暂存数据 no=i-1 while no >=0 and tmp <data[no]: data[no+1]=data[no] #就把所有元素往后推一个元素 no-=1 data[no+1]=tmp #最小的元素放到第一个位置 def main(): data = [16, 25, 39, 27, 12, 8, 45, 63] print('原始数据为:') showdata(data) insert(data) print('排序后的数据为:') showdata(data) main()
import random def inputarr(data, size): for i in range(size): data[i] = random.randint(0, 999) # 设置 data 值最大为 3 位数
def showdata(data, size): for i in range(size): print('%5d' % data[i], end='') print()
def radix(data, size): n = 1 # n为基数,从个位数开始排序 while n <= 100: tmp = [[0] * 100 for row in range(10)] # 设置暂存数组,[0~9位数][数据个数],所有内容均为0 for i in range(size): # 对比所有数据 m = (data[i] // n) % 10 # m为 n 位数的值,如 36 取十位数(36/10)%10=3 tmp[m][i] = data[i] # 把 data[i] 的值暂存在 tmp 中 k = 0 for i in range(10): for j in range(size): if tmp[i][j] != 0: # 因为一开始设置 tmp ={0},故不为 0 者即为 data[k] = tmp[i][j] # data 暂存在 tmp 中的值,把 tmp 中的值放 k += 1 # 回 data[ ]里 print('经过%3d位数排序后:' % n, end='') showdata(data, size) n = 10 * n
def interpolation_search(data,val): low=0 high=len(data)-1 while low<=high and val !=-1: mid=low+int((val-data[low])*(high-low)/(data[high]-data[low])) if val==data[mid]: return mid elif val <data[mid]: high=mid-1 else: low=mid+1 data=[1,2,5,6,8,11,14,17] val=3 print(interpolation_search(data,val))
常见的哈希算法有除留余数法,平方取中法,折叠法及数字分析法 0x5.4.1除留余数法 最简单的哈希函数是将数据除以某一个常数后,取余数来当索引 例子: 在一个有13个位置的数组中,只使用到7个地址,值分别是12,65,70,99,33,67,48。我们可以把数组内的值除以13,并以其余数来当数组的下标(作为索引),可以用以下式子表示: h(key)=key mod B
在折叠法中有两种做法,如上例直接将每一部分相加所得的值作为其bucket address,这种方法称为”移动折叠法”。哈希法的设计原则之一就是降低碰撞,如果希望降低碰撞的机会,就可以将上述每一部分数字中的奇数或偶数反转,再相加来取得其bucket address,这种改进的做法称为”边界折叠法”(folding at the boundaries)
第二步:其中100,472,438都发生碰撞,再使用第二种哈希函数f2 = h(key) = (key+2) MOD m,进行数据的地址
1 2 3
100 ---> h(100+2) = 102 mod 13 = 11 472 ---> h(472+2) = 474 mod 13 = 6 438 ---> h(438+2) = 440 mod 13 = 11
第三步:438仍发生碰撞问题,使用第三种哈希函数f3 = h(key) = (key+4) MOD m,重新进行438地址的安排
1
438 ---> h(438+4) = 442 mod 13 = 0
0x6 数组与链表算法
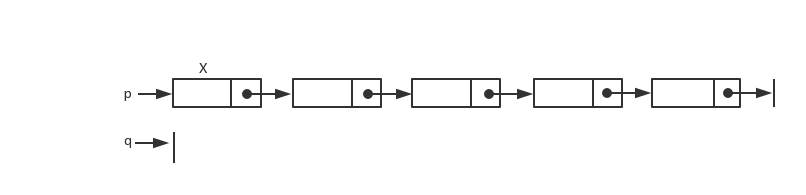
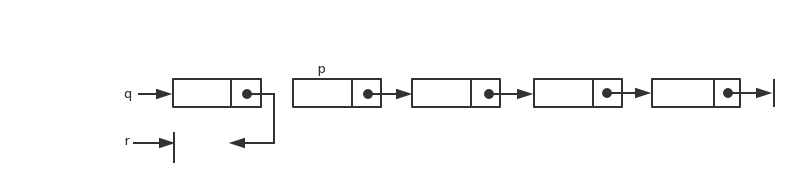
数组与链表都是相当重要的结构化数据类型(structured data type),也都是典型线性表的应用。按照内存存储的方式,基本上可分为以下两种方式: 1.静态数据结构(static data structure) 数据类型就是一种典型的静态数据结构,它使用连续分配的内存空间(contiguous allocation)来存储有序表中的数据。静态数据结构是在编译时就给相关的变量分配好内存空间。缺点是删除或加入数据时,需要移动大量的数据
2.动态数据结构(dynamic data structure) 动态数据结构又称为”链表”(linked list),它使用不连续的内存空间存储具有线性表特性的数据。优点是数据的插入或删除都相当方便,不需要移动大量数据
A=[[1,3,5],[7,9,11],[13,15,17]] B=[[9,8,7],[6,5,4],[3,2,1]] N=3 C=[[None]*N for row in range(N)] for i in range(3): for j in range(3): C[i][j]=A[i][j]+B[i][j] print('[矩阵A和矩阵B相加的结果]') for i in range(3): for j in range(3): print('%d'%C[i][j],end='\t') print()
def MatrixMultiply(arrA, arrB,arrC,M,N,P): global C if M<=0 or N<=0 or P<=0: print('[错误:维数M,N,P必须大于0]') return for i in range(M): for j in range(P): Temp=0 for k in range(N): Temp = Temp + int(arrA[i*N+k])*int(arrB[k*P+j]) arrC[i*P+j] = Temp
print('[请输入矩阵B的各个元素]') for i in range(N): for j in range(P): B[i*P+j]=input('b%d%d='%(i,j))
C=[None]*M*P #声明大小为MxP的列表C MatrixMultiply(A,B,C,M,N,P) print('[AxB的结果是]') for i in range(M): for j in range(P): print('%d' %C[i*P+j], end='\t') print()
for i in range(12): data[i][0]=i+1 data[i][1]=random.randint(51,100)
head1=employee() #建立第一组链表的头部 if not head1: print('Error!! 内存分配失败!!') sys.exit(0) head1.num=data[0][0] head1.name=namedata1[0] head1.salary=data[0][1] head1.next=None ptr=head1 for i in range(1,12): #建立第一组链表 newnode=employee() newnode.num=data[i][0] newnode.name=namedata1[i] newnode.salary=data[i][1] newnode.next=None ptr.next=newnode ptr=ptr.next for i in range(12): data[i][0]=i+13 data[i][1]=random.randint(51,100)
head2=employee() #建立第二组链表的头部 if not head2: print('Error!! 内存分配失败!!') sys.exit(0) head2.num=data[0][0] head2.name=namedata2[0] head2.salary=data[0][1] head2.next=None ptr=head2 for i in range(1,12): #建立第二组链表 newnode=employee() newnode.num=data[i][0] newnode.name=namedata2[i] newnode.salary=data[i][1] newnode.next=None ptr.next=newnode ptr=ptr.next i=0 ptr=concatlist(head1,head2) #将链表相连 print('两个链表相连的结果为:') while ptr!=None: #打印链表的数据 print('[%2d %6s %3d] => ' %(ptr.num,ptr.name,ptr.salary),end='') i=i+1 if i>=3: print() i=0 ptr=ptr.next
MAXSTACK = 100 # 定义堆栈的最大容量 global stack stack = [None] * MAXSTACK # 堆栈的数组声明 top = -1 # 堆栈的顶端
# 判断是否为空堆栈 def isEmpty(): if top == -1: return True else: return False
# 将指定的数据压入堆栈 def push(data): global top global MAXSTACK global stack if top >= MAXSTACK - 1: print('堆栈已满,无法再加入') else: top += 1 stack[top] = data # 将数据压入堆栈
# 从堆栈弹出数据*/ def pop(): global top global stack if isEmpty(): print('堆栈是空') else: print('弹出的元素为: %d' % stack[top]) top = top - 1
# 主程序 i = 2 count = 0 while True: i = int(input('要压入堆栈,请输入1,要弹出则输入0,停止操作则输入-1: ')) if i == -1: break elif i == 1: value = int(input('请输入元素值:')) push(value) elif i == 0: pop()
print('============================') if top < 0: print('\n 堆栈是空的') else: i = top while i >= 0: print('堆栈弹出的顺序为:%d' % (stack[i])) count += 1 i = i - 1 print
class Node: # 堆栈链结节点的声明 def __init__(self): self.data = 0 # 堆栈数据的声明 self.next = None # 堆栈中用来指向下一个节点 top = None
# 判断堆栈是否为空,是空返回1,否则返回0 def isEmpty(): global top if (top == None): return 1 else: return 0 # 将指定的数据压入堆栈 def push(data): global top new_add_node = Node() new_add_node.data = data # 将传入的值指定为节点的内容 new_add_node.next = top # 将新节点指向堆栈的顶端 top = new_add_node # 新节点成为堆栈的顶端
# 从堆栈弹出数据 def pop(): global top if isEmpty(): print('===目前为空堆栈===') return -1 else: ptr = top # 指向堆栈的顶端 top = top.next # 将堆栈顶端的指针指向下一个节点 temp = ptr.data # 弹出堆栈的数据 return temp # 将从堆栈弹出的数据返回给主程序
# 主程序 while True: i = int(input('要压入堆栈,请输入1,要弹出则输入0,停止操作则输入-1: ')) if i == -1: break elif i == 1: value = int(input('请输入元素值:')) push(value) elif i == 0: print('弹出的元素为%d' % pop())
print('============================') while (not isEmpty()): # 将数据陆续从顶端弹出 print('堆栈弹出的顺序为:%d' % pop())
global queen global number EIGHT = 8 # 定义堆栈的最大容量 queen = [None] * 8 # 存放8个皇后的行位置
number = 0 # 计算总共有几组解的总数 # 决定皇后存放的位置 # 输出所需要的结果 def print_table(): global number x = y = 0 number += 1 print('') print('八皇后问题的第%d组解\t' % number) for x in range(EIGHT): for y in range(EIGHT): if x == queen[y]: print('<q>', end='') else: print('<->', end='') print('\t') input('\n..按下任意键继续..\n') # 测试在(row,col)上的皇后是否遭受攻击 # 若遭受攻击则返回值为1,否则返回0 def attack(row, col): global queen i = 0 atk = 0 offset_row = offset_col = 0 while (atk != 1) and i < col: offset_col = abs(i - col) offset_row = abs(queen[i] - row) # 判断两皇后是否在同一行或在同一对角线上 if queen[i] == row or offset_row == offset_col: atk = 1 i = i + 1 return atk def decide_position(value): global queen i = 0 while i < EIGHT: if attack(i, value) != 1: queen[value] = i if value == 7: print_table() else: decide_position(value + 1) i = i + 1
def enqueue(item): # 将新数据加入Q的末尾,返回新队列 global rear global MAX_SIZE global queue if rear==MAX_SIZE-1: print("队列已满!") else: rear+=1 queue[rear]=item def dequeue(item): # 删除队列前端的数据,返回新队列 global rear global MAX_SIZE global front global queue if front==rear: print("队列为空!") else: front+=1 item=queue[front] def FRONT_VALUE(Queue): #返回队列前端的值 global rear global front global queue if front==rear: print("这是空队列!") else: print(queue[front])
def enqueue(name,score): global front global rear new_data=student() new_data.name=name new_data.score=score if rear==None: front=new_data else: rear.next=new_data rear=new_data new_data.next=None def dequeue(): global front global rear if front==None: print("队列已空!") else: print("姓名:%s\t成绩:%d...取出" %(front.name,front.score)) front=front.next
def dequeue(): # 取出队列中的数据 global front global rear if front == None: print('队列已空!') else: print('姓名:%s\t成绩:%d ....取出' %(front.name, front.score)) front = front.next # 将队列前端移到下一个元素 def show(): # 显示队列中的数据 global front global rear ptr = front if ptr == None: print('队列已空!') else: while ptr !=None: # 从front到rear遍历队列 print('姓名:%s\t成绩:%d' %(ptr.name, ptr.score)) ptr = ptr.next
select=0 while True: select=int(input('(1)加入 (2)取出 (3)显示 (4)离开 => ')) if select==4: break if select==1: name=input('姓名: ') score=int(input('成绩: ')) enqueue(name, score) elif select==2: dequeue() else: show()
class Node: def __init__(self): self.data=0 self.next=None front=Node() rear=Node() front=None rear=None
#方法enqueue:队列数据的加入 def enqueue(value): global front global rear node=Node() #建立节点 node.data=value node.next=None #检查是否为空队列 if rear==None: front=node #新建立的节点成为第1个节点 else: rear.next=node #将节点加入到队列的末尾 rear=node #将队列的末尾指针指向新加入的节点
#方法dequeue:队列数据的取出 def dequeue(action): global front global rear #从队列前端取出数据 if not(front==None) and action==1: if front==rear: rear=None value=front.data #将队列数据从前端取出 front=front.next #将队列的前端指针指向下一个 return value #从队列末尾取出数据 elif not(rear==None) and action==2: startNode=front #先记下队列前端的指针值 value=rear.data #取出队列当前末尾的数据 #查找队列末尾节点的前一个节点 tempNode=front while front.next!=rear and front.next!=None: front=front.next tempNode=front front=startNode #记录从队列末尾取出数据后的队列前端指针 rear=tempNode #记录从队列末尾取出数据后的队列末尾指针 #下一行程序是指当队列中仅剩下最后一个节点时, #取出数据后便将front和rear指向None if front.next==None or rear.next==None: front=None rear=None return value else: return -1 print('用链表来实现双向队列') print('====================================')
def Btree_create(btree,data,length): for i in range(1,length): level=1 while btree[level]!=0: if data[i]>btree[level]: #如果数组内的值大于树根,则往右子树比较 level=level*2+1 else: #如果数组内的值小于或等于树根,则往左子树比较 level=level*2 btree[level]=data[i] #把数组值放入二叉树 length=9 data=[0,6,3,5,4,7,8,9,2] #原始数组 btree=[0]*16 #存放二叉树数组 print('原始数组内容:') for i in range(length): print('[%2d] ' %data[i],end='') print('') Btree_create(btree,data,9) print('二叉树内容:') for i in range(1,16): print('[%2d] ' %btree[i],end='') print()
class tree: def __init__(self): self.data=0 self.left=None self.right=None
def create_tree(root,val): #建立二叉树的函数 newnode=tree() newnode.data=val newnode.left=None newnode.right=None if root==None: root=newnode return root else: current=root while current!=None: backup=current if current.data > val: current=current.left else: current=current.right if backup.data >val: backup.left=newnode else: backup.right=newnode return root
data=[5,6,24,8,12,3,17,1,9] ptr=None root=None for i in range(9): ptr=create_tree(ptr,data[i]) #建立二叉树 print('左子树:') root=ptr.left while root!=None: print('%d' %root.data) root=root.left print('--------------------------------') print('右子树:') root=ptr.right while root!=None: print('%d' %root.data) root=root.right print()
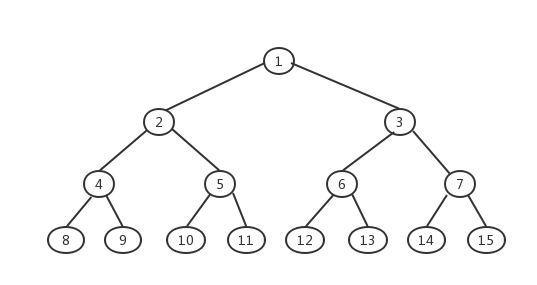
0x8.3二叉树遍历 所谓二叉树的遍历(Binary Tree Traversal),最简单的说法就是”访问树中所有的节点各一次”,并且在遍历后,将树中的数据转化为线性关系
for i in range(11): ptr=create_tree(ptr,arr[i]) #建立二叉树 print('[%2d] ' %arr[i],end='') print() data=int(input('请输入要查找的键值:')) if search(ptr,data)!=None: #在二叉树中查找 print('二叉树中有此节点了!') else: ptr=create_tree(ptr,data) inorder(ptr)
#广度优先查找法 def bfs(current): global front global rear global Head global run enqueue(current) #将第一个顶点存入队列 run[current]=1 #将遍历过的顶点设置为1 print('[%d]' %current, end='') #打印出该遍历过的顶点 while front!=rear: #判断当前的队伍是否为空 current=dequeue() #将顶点从队列中取出 tempnode=Head[current].first #先记录当前顶点的位置 while tempnode!=None: if run[tempnode.x]==0: enqueue(tempnode.x) run[tempnode.x]=1 #记录已遍历过 print('[%d]' %tempnode.x,end='') tempnode=tempnode.next
class Node: def __init__(self,x): self.x=x #顶点数据 self.next=None #指向下一个顶点的指针 class GraphLink: def __init__(self): self.first=None self.last=None def my_print(self): current=self.first while current!=None: print('[%d]' %current.x,end='') current=current.next print()
def insert(self,x): newNode=Node(x) if self.first==None: self.first=newNode self.last=newNode else: self.last.next=newNode self.last=newNode #队列数据的存入 def enqueue(value): global MAXSIZE global rear global queue if rear>=MAXSIZE: return rear+=1 queue[rear]=value
#队列数据的取出 def dequeue(): global front global queue if front==rear: return -1 front+=1 return queue[front]
#广度优先查找法 def bfs(current): global front global rear global Head global run enqueue(current) #将第一个顶点存入队列 run[current]=1 #将遍历过的顶点设置为1 print('[%d]' %current, end='') #打印出该遍历过的顶点 while front!=rear: #判断当前的队伍是否为空 current=dequeue() #将顶点从队列中取出 tempnode=Head[current].first #先记录当前顶点的位置 while tempnode!=None: if run[tempnode.x]==0: enqueue(tempnode.x) run[tempnode.x]=1 #记录已遍历过 print('[%d]' %tempnode.x,end='') tempnode=tempnode.next
#声明图的边线数组 Data=[[0]*2 for row in range(20)]
Data =[[1,2],[2,1],[1,3],[3,1],[2,4], \ [4,2],[2,5],[5,2],[3,6],[6,3], \ [3,7],[7,3],[4,5],[5,4],[6,7],[7,6],[5,8],[8,5],[6,8],[8,6]]
run=[0]*9 #用来记录各顶点是否遍历过 queue=[0]*MAXSIZE Head=[GraphLink]*9 print('图的邻接表内容:') #打印图的邻接表内容 for i in range(1,9): #共有8个顶点 run[i]=0 #把所有顶点设置成尚未遍历过 print('顶点%d=>' %i,end='') Head[i]=GraphLink() for j in range(20): if Data[j][0]==i: #如果起点和链表头相等,则把顶点加入链表 DataNum = Data[j][1] Head[i].insert(DataNum) Head[i].my_print() #打印图的邻接标内容



























评论