


这两天想学一下验证码的识别,那就拿简单的入手吧,也不舍近求远了,就拿大乌云的验证码试试吧。
乌云的验证码很规则简单,以前也有人做过实验,基本图片都没有什么干扰。
基本的思路就是验证码图片二值化,分割图片,与之前分割好的单个验证码比较(乌云的验证码好像没有0、1、O、I)。
既然验证码就是两种颜色,处理起来就简单了,首先判断验证码是什么颜色,如果黑色,正常处理,白色的话,白色变黑色,其他颜色变白色。
一开始处理下面这种类型的验证码有点问题,根据验证码颜色来处理,背景颜色复杂点都无所谓了。

下面给出代码,注释掉的代码为前期调试的代码,主要用于去背景,分割图片,然后得到单个字符,这些单个字符坐字库来做标准,用于比较,共32个(0、1、O、I没有),这个大家自己去做吧,不用上传附件了,还有jar包自己去下载吧。
乌云大大来个赞吧。
package cn.pwntcha.test;
import java.awt.Color;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.io.OutputStream;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import javax.imageio.ImageIO;
import org.apache.commons.httpclient.HttpClient;
import org.apache.commons.httpclient.HttpStatus;
import org.apache.commons.httpclient.methods.GetMethod;
import org.apache.commons.io.IOUtils;
public class Wooyun {
public static void main(String[] args) throws Exception {
// 下载图片
downloadImage();
// 处理图片
// for (int i = 0; i images = splitImage(img);
// int j = 0;
// for (BufferedImage bufferedImage : images) {
// j++;
// ImageIO.write(bufferedImage, "jpg", new File("wooyun" + i
// + "_" + j + "_.jpg"));
// }
// }
// 识别图片
for (int i = 0; i 10) {// 验证码为纯黑的背景偏白,否则验证码白色背景偏黑
return 0;
} else {
return 1;
}
}
// 验证码为白色时,白色变为黑色,其他颜色全为白色
public static void change(BufferedImage img) {
int width = img.getWidth();
int height = img.getHeight();
for (int x = 0; x 100) {
return 1;
}
return 0;
}
public static BufferedImage removeBackgroud(String picFile)
throws Exception {
BufferedImage img = ImageIO.read(new File(picFile));
if (getCaptchaBackgroud(img) == 1) {
change(img);
}
int width = img.getWidth();
int height = img.getHeight();
for (int x = 0; x splitImage(BufferedImage img)
throws Exception {
List subImgs = new ArrayList();
subImgs.add(img.getSubimage(14, 4, 8, 10));
subImgs.add(img.getSubimage(23, 4, 8, 10));
subImgs.add(img.getSubimage(32, 4, 8, 10));
subImgs.add(img.getSubimage(41, 4, 8, 10));
return subImgs;
}
public static Map loadTrainData() throws Exception {
Map map = new HashMap();
File dir = new File("wooyuntrain");
File[] files = dir.listFiles();
for (File file : files) {
map.put(ImageIO.read(file), file.getName().charAt(0) + "");
}
return map;
}
public static String getAllOcr(String file) throws Exception {
BufferedImage img = removeBackgroud(file);
List listImg = splitImage(img);
Map map = loadTrainData();
String result = "";
for (BufferedImage bi : listImg) {
result += getSingleCharOcr(bi, map);
}
ImageIO.write(img, "JPG",
new File("wooyunresult" + result + ".jpg"));
return result;
}
public static String getSingleCharOcr(BufferedImage img,
Map map) {
String result = "";
int width = img.getWidth();
int height = img.getHeight();
int min = width * height;
for (BufferedImage bi : map.keySet()) {
int count = 0;
Label1: for (int x = 0; x = min)
break Label1;
}
}
}
if (count
相关内容:
论防刷票、恶意提交表单:公司网站被恶意提交订单,看你如何解决?
身为码农,为12306说两句公道话,前淘宝工程师发帖谈12306:几乎是奇迹!
BurpSuite有点“懒”,你们是怎样完成带验证码爆破的?
短信炸弹,短信轰炸,利用各大网站的验证码功能批量轰炸某个号码
各种吐槽:
1#
he1renyagao (
前排占位
2#
寂寞的瘦子 (我喜欢放荡不羁的编程,所以选择动态语言。) | 2014-04-21 18:06
java果然长,用python只要几行。不过我用python写的识别率不能到100%,不会处理图片!--
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
import Image
import tesseract
def Captcha(filepath):
im = Image.open(filepath)
im = im.convert("P")
im2 = Image.new("P",im.size,255)
im = im.convert("P")
histo = im.histogram()
if histo[0]== 0: #white
for x in range(im.size[1]):
for y in range(im.size[0]):
pix = im.getpixel((y,x))
if pix == 225:
im2.putpixel((y,x),0)
else:
for x in range(im.size[1]):
for y in range(im.size[0]):
pix = im.getpixel((y,x))
if pix == 0:
im2.putpixel((y,x),0)
im2.save('10.png')
api = tesseract.TessBaseAPI()
api.Init(".","eng",tesseract.OEM_DEFAULT)
api.SetVariable("tessedit_char_whitelist", "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ")
api.SetPageSegMode(tesseract.PSM_AUTO)
mImgFile = "10.png"
mBuffer=open(mImgFile,"rb").read()
result = tesseract.ProcessPagesBuffer(mBuffer,len(mBuffer),api)
if not result:
api = tesseract.TessBaseAPI()
api.Init(".","eng",tesseract.OEM_DEFAULT)
api.SetVariable("tessedit_char_whitelist", "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ")
api.SetPageSegMode(tesseract.PSM_AUTO)
mImgFile = filepath
mBuffer=open(mImgFile,"rb").read()
result = tesseract.ProcessPagesBuffer(mBuffer,len(mBuffer),api)
return result[:4]
else:
return result[:4]
3#
xsser (十根阳具有长短!!) | 2014-04-21 18:09
日
4#
浮生若梦 | 2014-04-21 18:33
二值化,分割,轻松搞定。。。。。
5#
[email protected] | 2014-04-21 18:47
好像很牛比的样子
6#
小威 (呵呵复呵呵,女神敲回车!) | 2014-04-21 18:50
一大波爆破僵尸正在靠近~
7#
Mujj (Krypt VPS特价www.80host.com) | 2014-04-21 18:51
贱心的豆豆……
8#
ylaxfcy | 2014-04-21 18:52
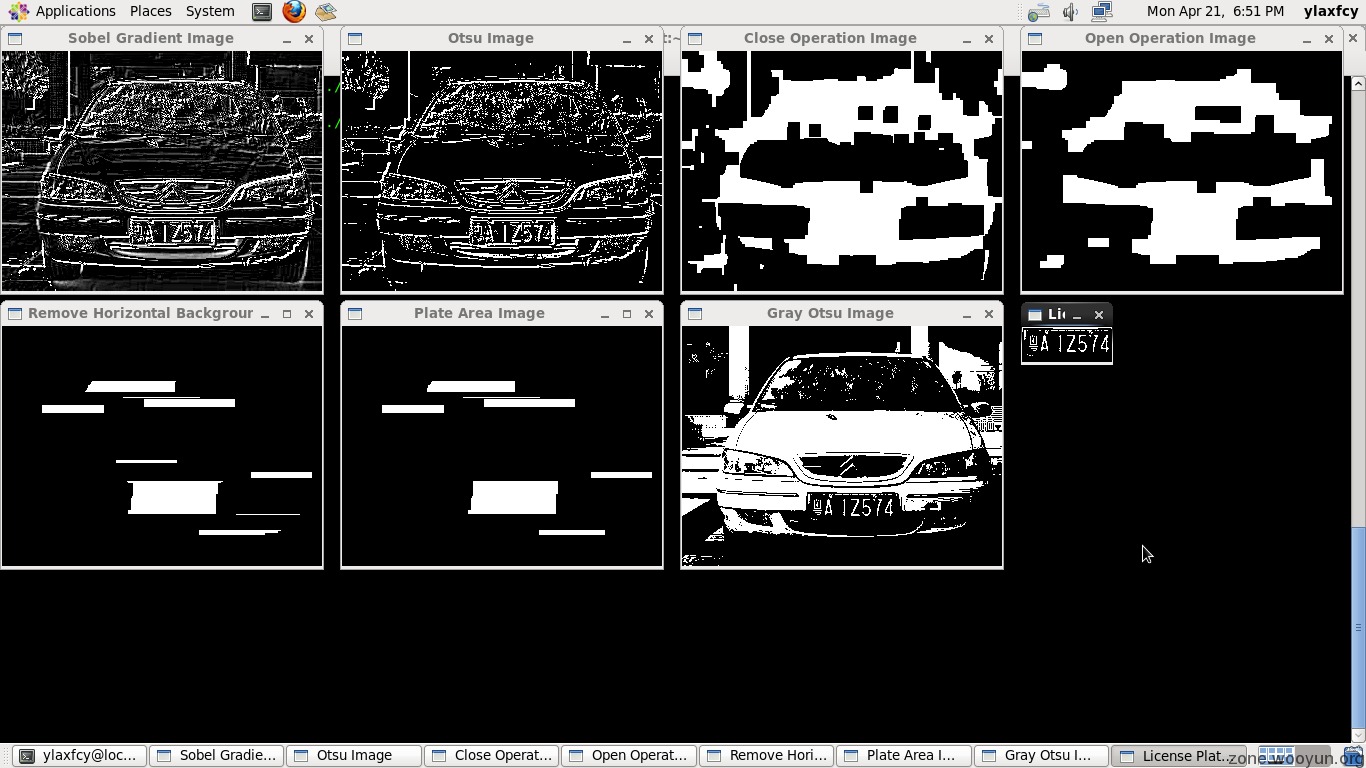
验证码识别还是好做,至少没有复杂背景什么,最近在做毕设,图像处理识别类的,代码已超过1.5k
9#
ylaxfcy | 2014-04-21 18:53
效果图
![]()
10#
ylaxfcy | 2014-04-21 18:54
怎么大图显示不全。。。。没过缩放么?
11#
廷廷 (想法最重要) | 2014-04-21 19:16
@ylaxfcy 膜拜···················
12#
小乐天 (Web安全只能当兴趣) | 2014-04-21 19:20
make
13#
大和尚 (www.ieroot.com) | 2014-04-21 20:01
车牌识别太easy了.
14#
insight-labs (Root Yourself in Success) | 2014-04-21 20:02
@ylaxfcy 搞那么复杂干什么,直接用opencv啊
15#
寂寞的瘦子 (我喜欢放荡不羁的编程,所以选择动态语言。) | 2014-04-21 20:04
@ylaxfcy 感觉你这个可以先定位车牌区域的坐标然后截取出来再处理
16#
ylaxfcy | 2014-04-21 20:12
@大和尚 你来试试。。
17#
ylaxfcy | 2014-04-21 20:15
@insight-labs 不准用opencv啊,我就显示载入和显示图像用来opencv,然后用了一下他的基础数据结构,然后算法都自己实现,最后在把载入图片和基础数据结构实现了,然后搞到有gpu的板子上面去跑。
18#
ylaxfcy | 2014-04-21 20:16
@insight-labs 成功率不高,在别人的算法基础上做优化都只成功75%左右,不知道那些论文里面95%+是怎么做出来的
19#
ylaxfcy | 2014-04-21 20:17
@寂寞的瘦子 对,是这样的,做到车牌定位与分割就1500行了
20#
寂寞的瘦子 (我喜欢放荡不羁的编程,所以选择动态语言。) | 2014-04-21 20:51
@ylaxfcy 掉渣。。
21#
高斯 | 2014-04-21 21:19
二值化 去噪 分割
文章来源于lcx.cc:识别wooyun的验证码,wooyun验证码识别,识别乌云验证码的详细分析
相关推荐: Real-World CSRF attack hijacks DNS Server configuration of TP-Link routers
Introduction Analysis of the exploit Analysis of the CSRF payload Consequences of a malicious DNS server Prevalence of the exploit…
- 左青龙
- 微信扫一扫
-

- 右白虎
- 微信扫一扫
-

评论